
Python入門22ではファイル入出力を学びました。ここからはアルゴリズムの世界に入ります。まずは「データの中から目的のものを探す」探索アルゴリズムから始めましょう。

まずはPycoBlocksを開こう
下のPycoBlocksで直接作業するか、別タブで開き、生成されるPythonコードを見ながら進めてください。
用語を整理しよう
| 用語 | 意味 |
|---|---|
| 線形探索 | 先頭から順番に1つずつ調べる探索方法 |
| 計算量 O(n) | データが n 個のとき、最大 n 回の比較が必要 |
| 番兵法 | リスト末尾に目標値を追加して「必ず見つかる」ようにする工夫 |
| ソート不要 | データが並び替えられていなくても使える |
ステップ1:線形探索の仕組み
線形探索は探索アルゴリズムの中でもっともシンプルな方法です。リストの先頭から末尾に向かって、要素を一つずつ目標値と比べていきます。途中で見つかったらそこで終了し、最後まで見つからなければ「なかった」と返します。データが整列されていなくても使えるのが大きな特徴です。
PycoBlocks では関数を作るのに py_def_args2(2つの引数を持つ関数定義)を使い、繰り返し部分は pico_for_range(インデックス i を 0 から順に動かす for ループ)、リスト操作には py_list_len(長さ)と py_list_get(要素取り出し)、結果を返すには py_return を組み合わせます。
たとえばリスト [5, 3, 9, 1, 7] の中から値 9 を探す場合、インデックス 0 番目の 5、1 番目の 3、2 番目の 9、と順に取り出して比べ、3 回目の比較で見つかります。見つかった時点で return i によって関数を抜けるので、それ以降の要素は調べません。
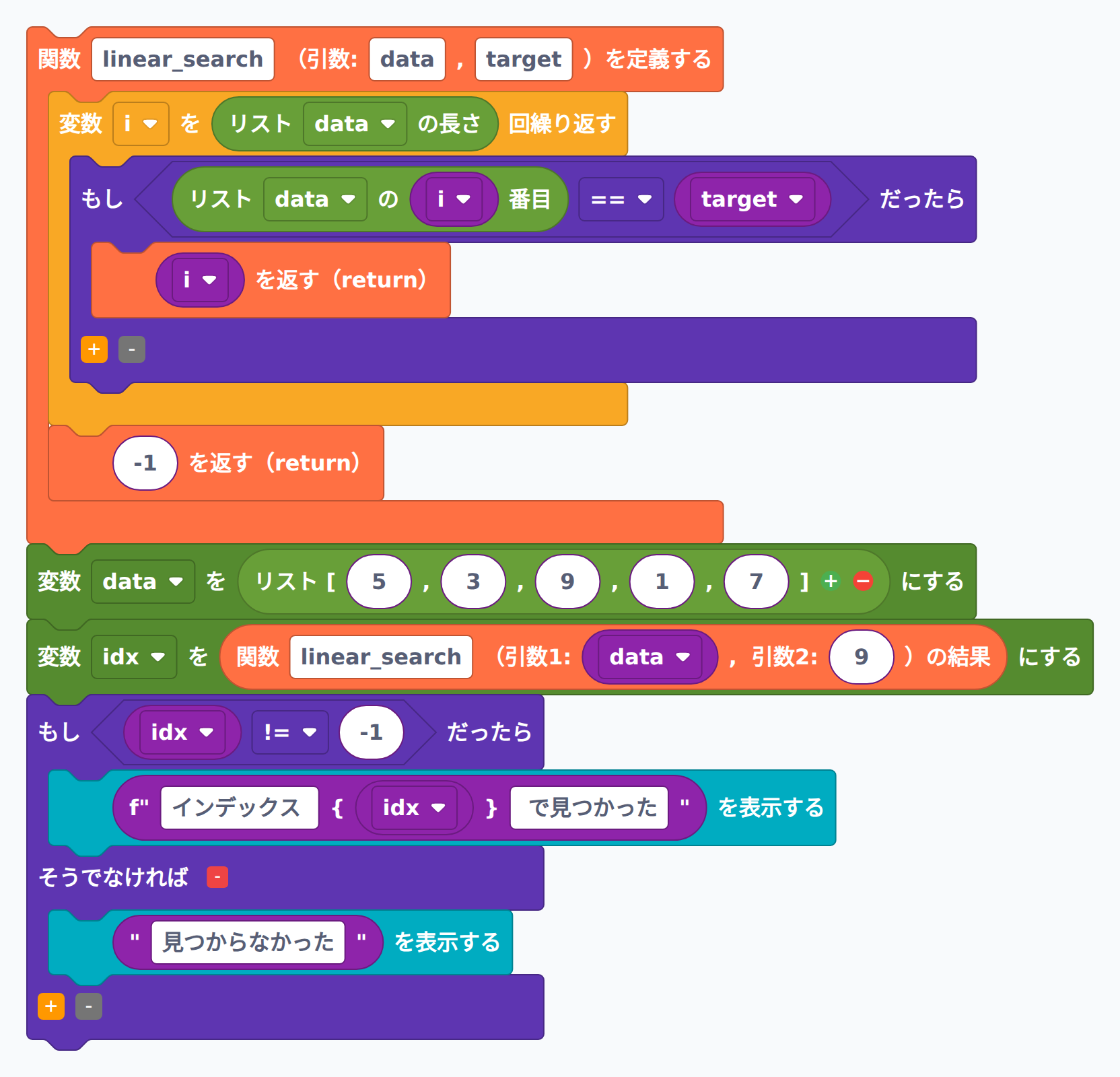
def linear_search(data, target):
for i in range(len(data)):
if data[i] == target:
return i # 見つかったインデックスを返す
return -1 # 見つからなかった
data = [5, 3, 9, 1, 7]
idx = linear_search(data, 9)
if idx != -1:
print(f"インデックス {idx} で見つかった")
else:
print("見つからなかった")
ステップ2:for-in ループでシンプルに書く
「値があるかどうかだけ知りたい」場合は、Python の in 演算子を使うと if 9 in data: のようにとても短く書けます。位置(インデックス)まで知りたいときは enumerate を使うと、番号と値の両方をまとめて取り出せます。番兵となるインデックス計算が不要になり、コードがすっきりします。
PycoBlocks では py_list_contains(要素が含まれるか)と py_enumerate_for(番号と値で順に繰り返す)の2つのブロックを組み合わせます。
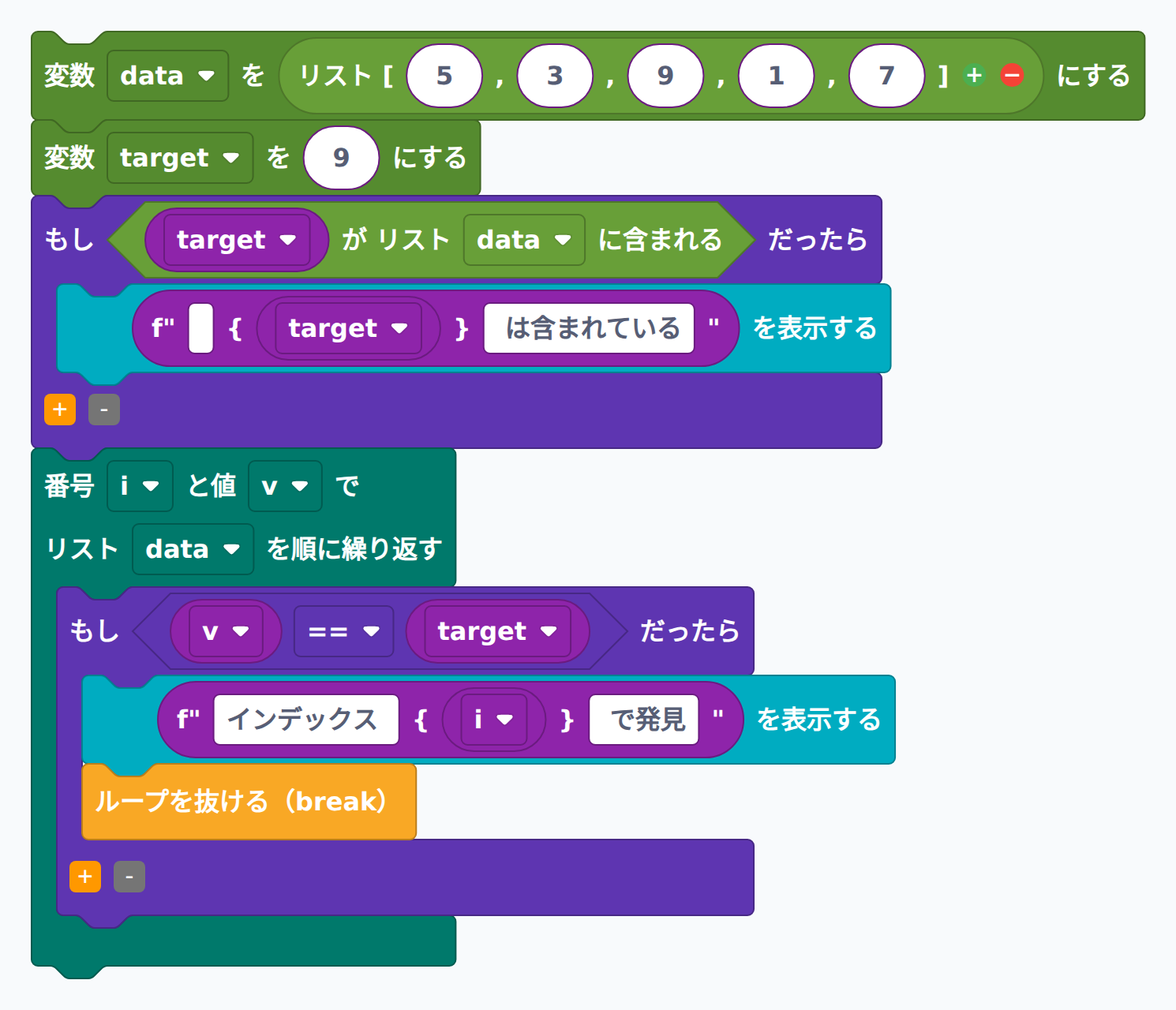
data = [5, 3, 9, 1, 7]
target = 9
# in 演算子で存在確認(最も短い書き方)
if target in data:
print(f"{target} は含まれている")
# 値が見つかった位置も調べる場合
for i, v in enumerate(data):
if v == target:
print(f"インデックス {i} で発見")
break
ステップ3:計算量 O(n) とは
計算量(オーダー)とは「データの量が増えたときに、処理時間がどう増えるか」を表す目安です。線形探索の計算量は O(n)(オー・エヌ)と書き、データが n 個あれば最悪の場合 n 回の比較が必要、という意味になります。
下のプログラムでは、リストの最後の要素を線形探索で見つけ、何回比較したかを数えます。100件のリストでは100回、10000件のリストでは10000回の比較が必要なことが確認でき、データ数に比例して比較回数が増えることが体感できます。
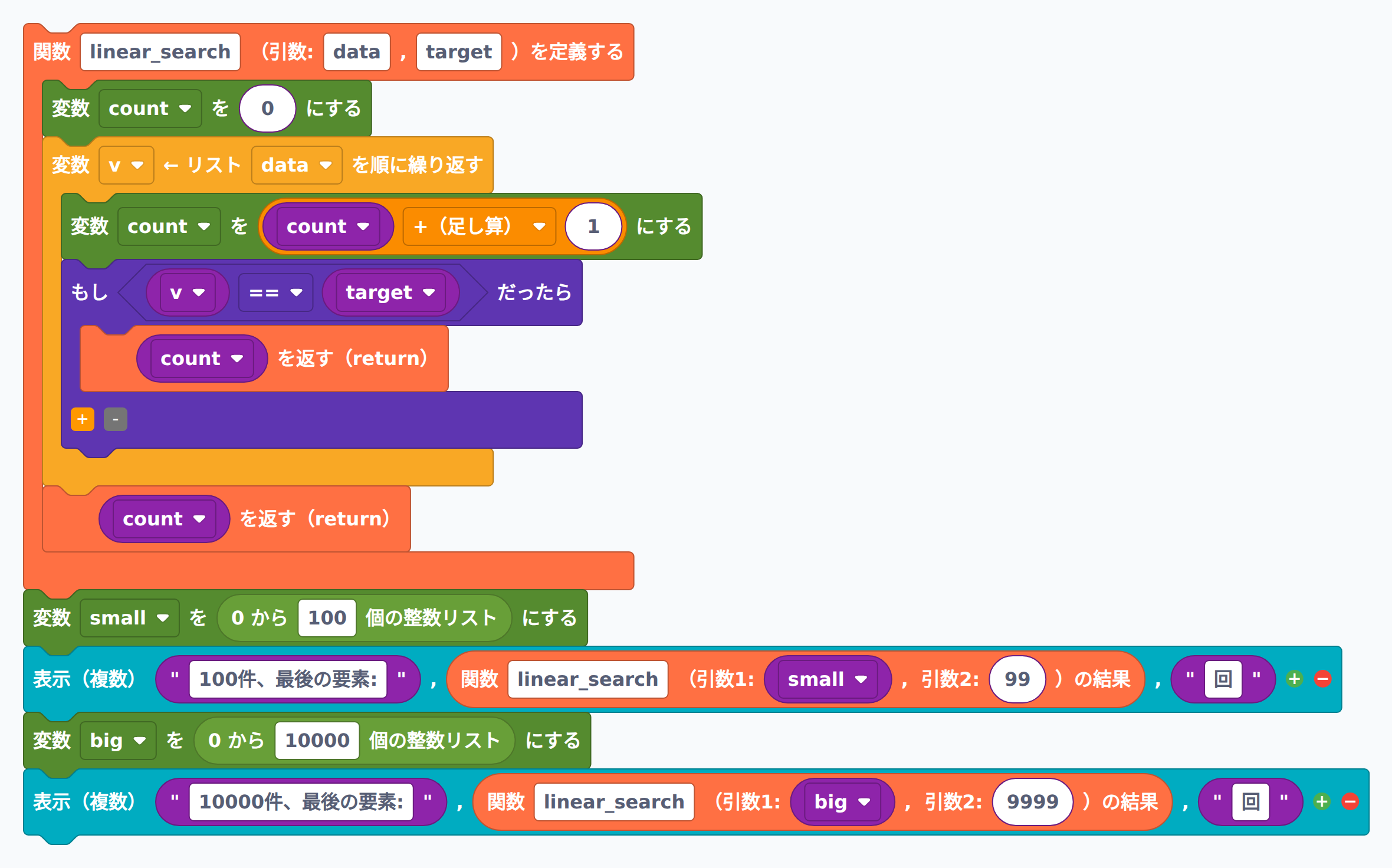
# 計算量を体感する実験
def linear_search(data, target):
count = 0
for v in data:
count += 1
if v == target:
return count
return count
# 小さいリスト
small = list(range(100))
print("100件、最後の要素:", linear_search(small, 99), "回")
# 大きいリスト
big = list(range(10000))
print("10000件、最後の要素:", linear_search(big, 9999), "回")
# データが100倍になると比較回数も約100倍になる → O(n)
ステップ4:番兵法(センチネル)
番兵法(センチネル法)は、ループの中の条件チェックを減らすための工夫です。普通の線形探索では「最後まで来たか?」と「目標値と一致したか?」の2つを毎回チェックする必要がありますが、リストの末尾にあらかじめ目標値そのものを追加しておくと、必ずどこかで一致が起こるため「最後まで来たか?」のチェックが不要になります。
PycoBlocks では、末尾追加に py_list_append、繰り返しに py_while、用が済んだ番兵を取り除くのに py_list_pop を使います。最後に i < n(元のリストの範囲内に見つかったか)を確認することで、本当に見つかったかどうかを判定します。
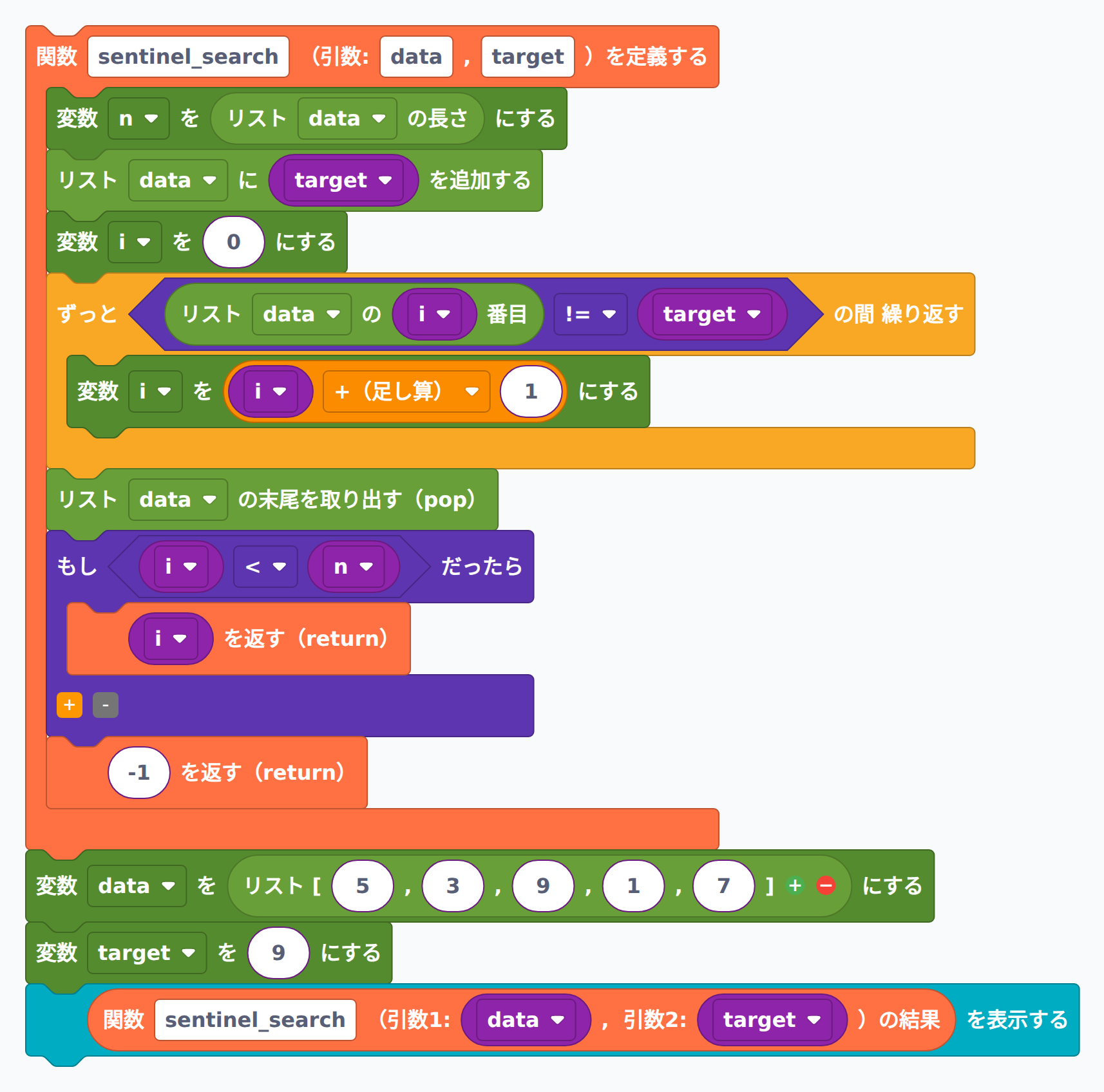
def sentinel_search(data, target):
n = len(data)
data.append(target) # 番兵を末尾に追加
i = 0
while data[i] != target:
i += 1
data.pop() # 番兵を削除
if i < n:
return i
return -1
data = [5, 3, 9, 1, 7]
target = 9
print(sentinel_search(data, target)) # 2
# target を 4 など含まれない値にすると -1 が返る
コーディングモードで書いてみよう
ブロックで動きを確認したら、コードで実装してみましょう。線形探索は実用的な場面でよく登場します。
例1:テスト結果から合格者を探す
students = [
{"name": "田中", "score": 72},
{"name": "鈴木", "score": 91},
{"name": "佐藤", "score": 55},
{"name": "山田", "score": 88},
{"name": "中村", "score": 63},
]
threshold = 80
print("合格者(80点以上):")
for s in students:
if s["score"] >= threshold:
print(f" {s['name']}:{s['score']}点")
合格条件を変えるだけで、60点以上・95点以上など応用できます。リストの全要素を順番にチェックする——これが線形探索の本質です。
例2:Python組み込みの探索と比較する
data = [15, 3, 42, 8, 27, 3, 99]
# 自作線形探索
def my_find(lst, val):
for i, v in enumerate(lst):
if v == val:
return i
return -1
# Pythonの組み込みメソッド(内部は線形探索)
print(my_find(data, 42)) # 2
print(data.index(42)) # 2(同じ結果)
print(3 in data) # True
print(data.count(3)) # 2(値3は2個ある)
list.index() や in 演算子は内部で線形探索を使っています。自分で実装できると、組み込みメソッドの動きも理解しやすくなります。
演習課題
課題2-1-1:最初に現れる位置を返す
リスト [4, 2, 7, 2, 9, 2] から値 2 が最初に現れるインデックスを返す関数を書いてください。見つからない場合は -1 を返すようにしてください。
▶ 模範解答と解説を見る
ブロックの組み合わせ例(スクリーンショット):
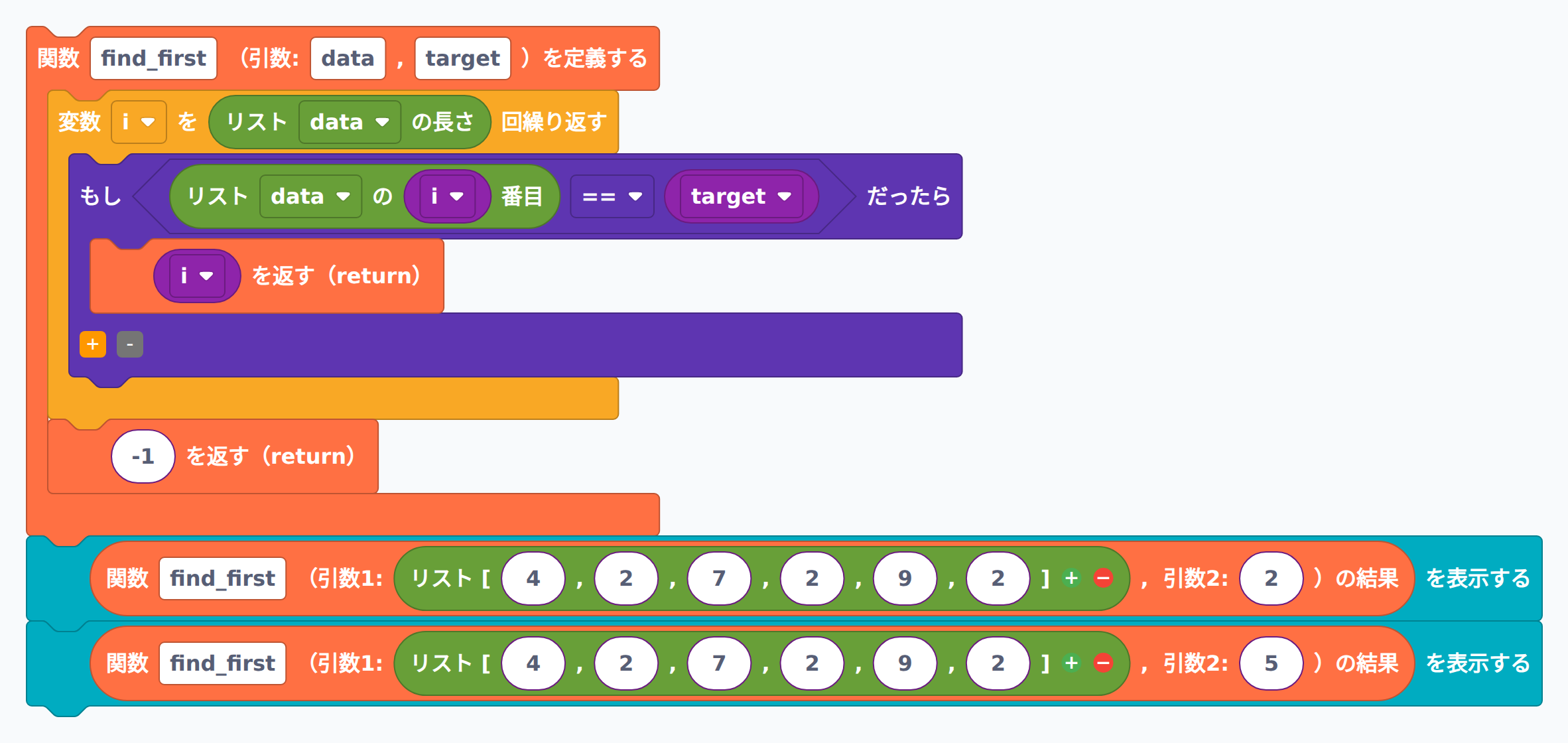
def find_first(data, target):
for i in range(len(data)):
if data[i] == target:
return i
return -1
print(find_first([4, 2, 7, 2, 9, 2], 2)) # 1
print(find_first([4, 2, 7, 2, 9, 2], 5)) # -1
解説: リストの先頭から順番に比べていき、最初に一致した位置で return i によって関数を抜けます。それ以降の要素は調べないので、見つかれば早く終わります。リスト末尾まで一度も一致しなければ return -1 で「見つからなかった」を伝えます。実行例では 2 が最初に登場するインデックスは 1、値 5 は含まれていないので -1 が返ります。
課題2-1-2:全ての出現位置を返す
リスト [4, 2, 7, 2, 9, 2] から値 2 が現れる全てのインデックスをリストで返す関数を書いてください。
▶ 模範解答と解説を見る
ブロックの組み合わせ例(スクリーンショット):
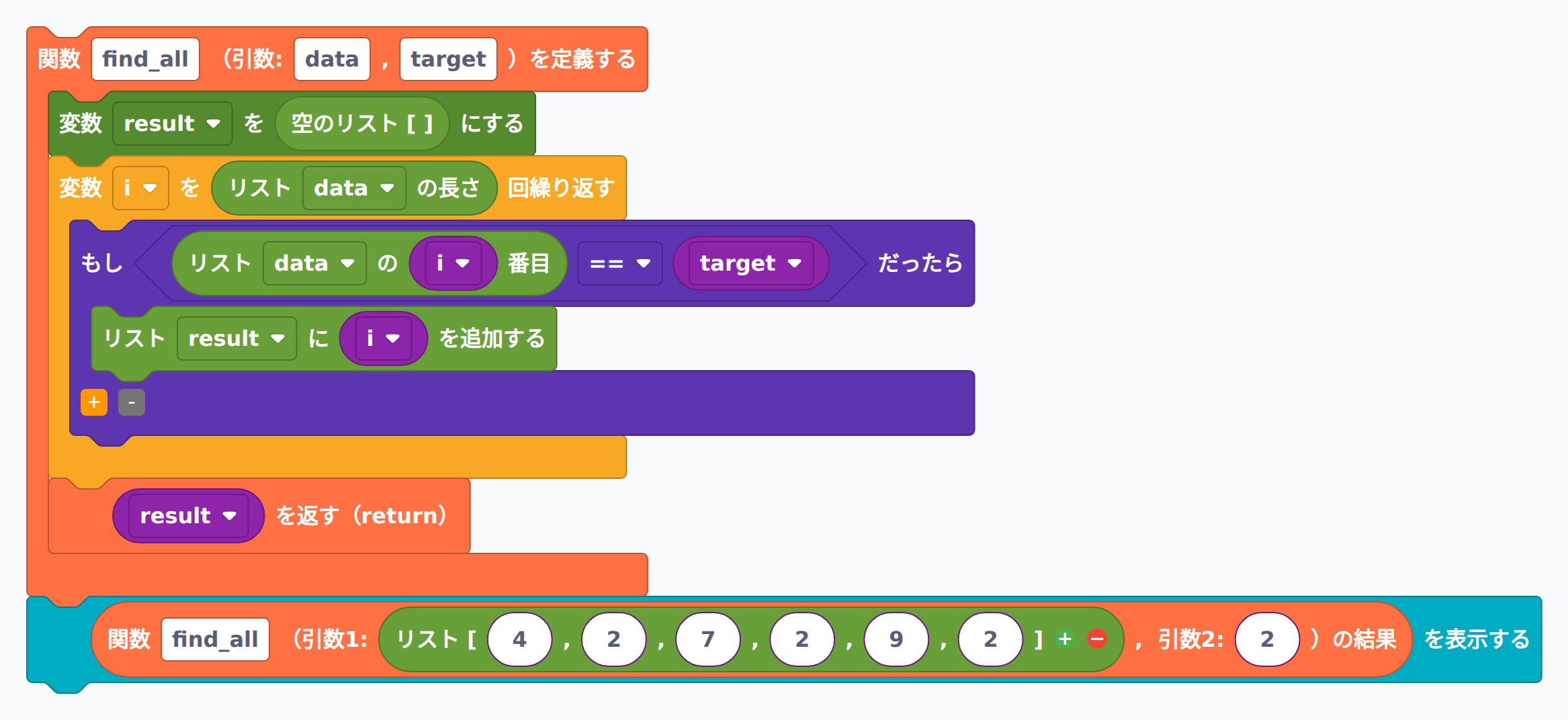
def find_all(data, target):
result = []
for i in range(len(data)):
if data[i] == target:
result.append(i)
return result
print(find_all([4, 2, 7, 2, 9, 2], 2)) # [1, 3, 5]
解説: 課題2-1-1 と違い、最初に見つかっても return せず、最後まで調べきります。一致するたびに result.append(i) でインデックスをリストに追加し、ループを抜けてから一括で返します。値 2 はインデックス 1, 3, 5 の3か所に登場するので、結果は [1, 3, 5] になります。一度も登場しないときは空リスト [] が返り、これは「該当なし」を表現する自然な返り値です。
課題2-1-3:最大値の位置を探す
線形探索の考え方で、リストの最大値が入っているインデックスを返す関数を書いてください。
▶ 模範解答と解説を見る
ブロックの組み合わせ例(スクリーンショット):
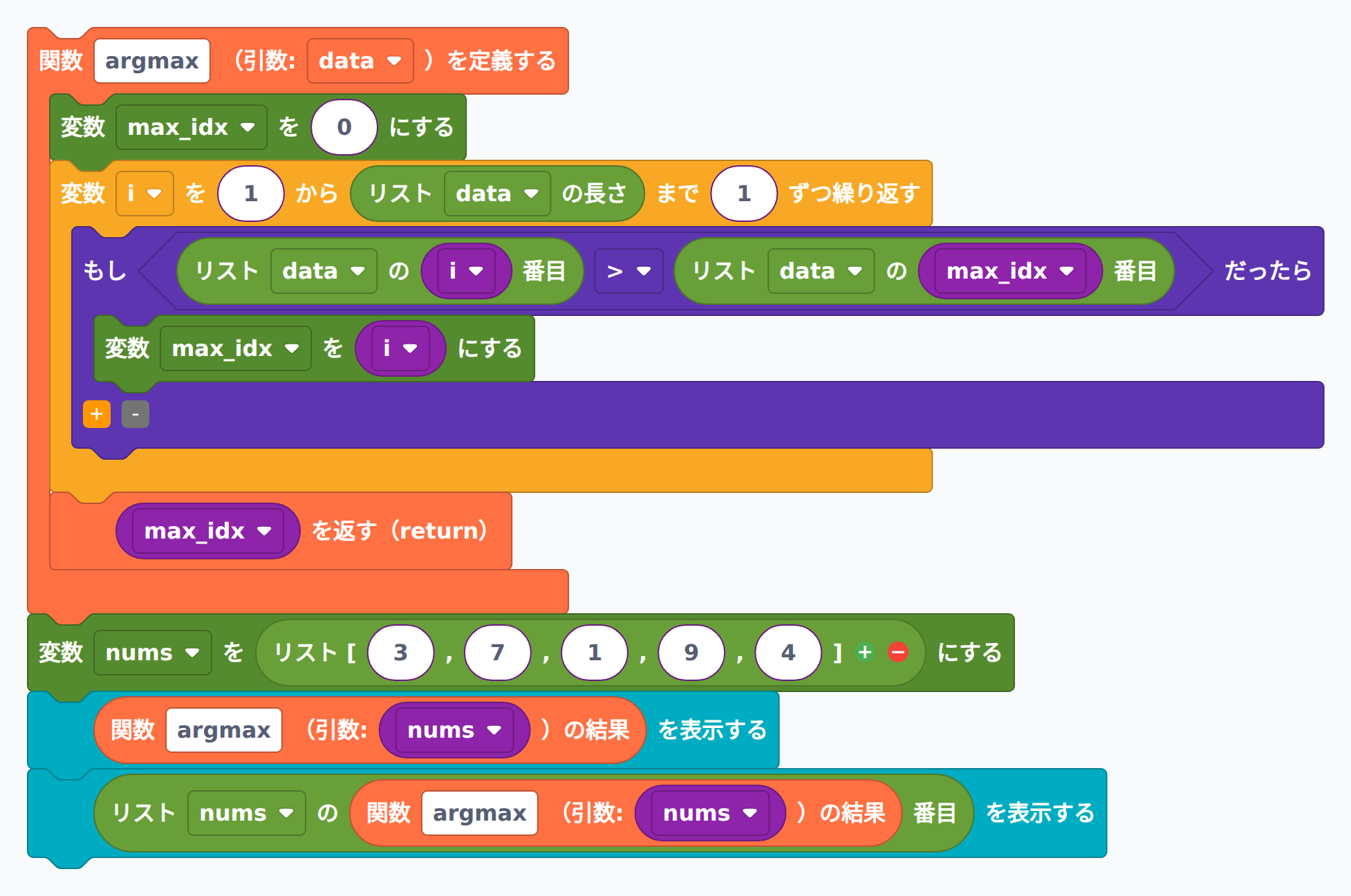
def argmax(data):
max_idx = 0
for i in range(1, len(data)):
if data[i] > data[max_idx]:
max_idx = i
return max_idx
nums = [3, 7, 1, 9, 4]
print(argmax(nums)) # 3(インデックス3の値9が最大)
print(nums[argmax(nums)]) # 9
解説: 「いま分かっている中で一番大きい値の位置」を max_idx に覚えておき、リストを順に走査して、それより大きい値が見つかるたびに max_idx を更新します。最初は先頭(インデックス 0)を暫定の最大とするので、ループはインデックス 1 から始めます。これは Python 標準の max() 関数と同じ考え方ですが、自分で書けると応用がききます。
課題2-1-4:線形探索で名前を検索
辞書のリスト [{"name": "田中", "score": 85}, {"name": "鈴木", "score": 92}, {"name": "山田", "score": 78}] から名前 "鈴木" を線形探索して点数を表示するプログラムを書いてください。
▶ 模範解答と解説を見る
ブロックの組み合わせ例(スクリーンショット):
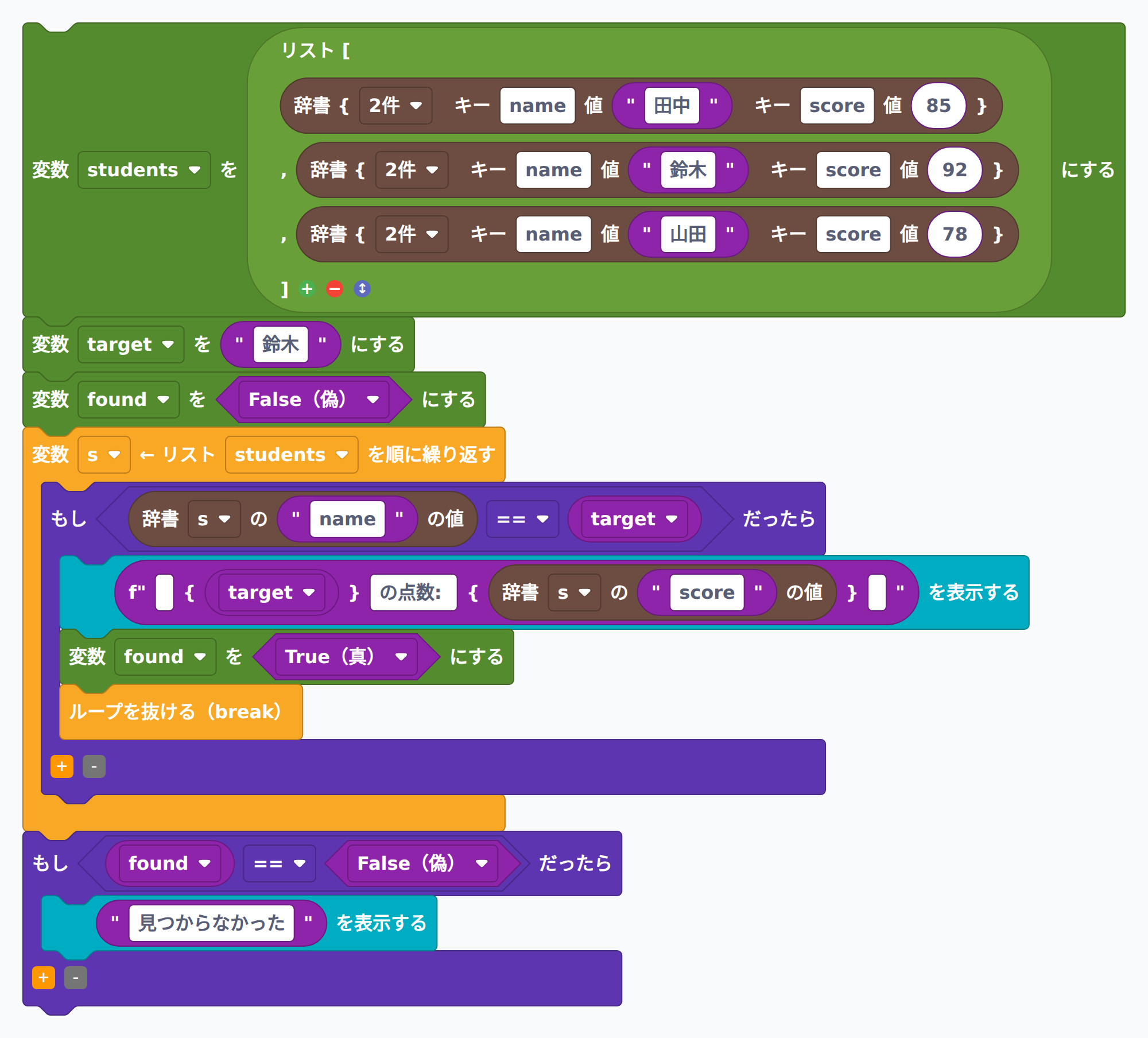
students = [
{"name": "田中", "score": 85},
{"name": "鈴木", "score": 92},
{"name": "山田", "score": 78}
]
target = "鈴木"
found = False
for s in students:
if s["name"] == target:
print(f"{target}の点数: {s['score']}")
found = True
break
if found == False:
print("見つからなかった")
解説: 見つかったかどうかを記録する found フラグを使うと、ループを抜けたあとで「見つからなかった場合の処理」を行えます。Python には for-else 構文もあり、その場合は break されずにループが終わったときだけ else ブロックが実行されます。
課題2-1-5:何回目で見つかるかを測る
list(range(1000)) に対して、値 777 を線形探索し、何回目の比較で見つかったか表示するプログラムを書いてください。また、値 1500 の場合も確認しましょう。
▶ 模範解答と解説を見る
ブロックの組み合わせ例(スクリーンショット):
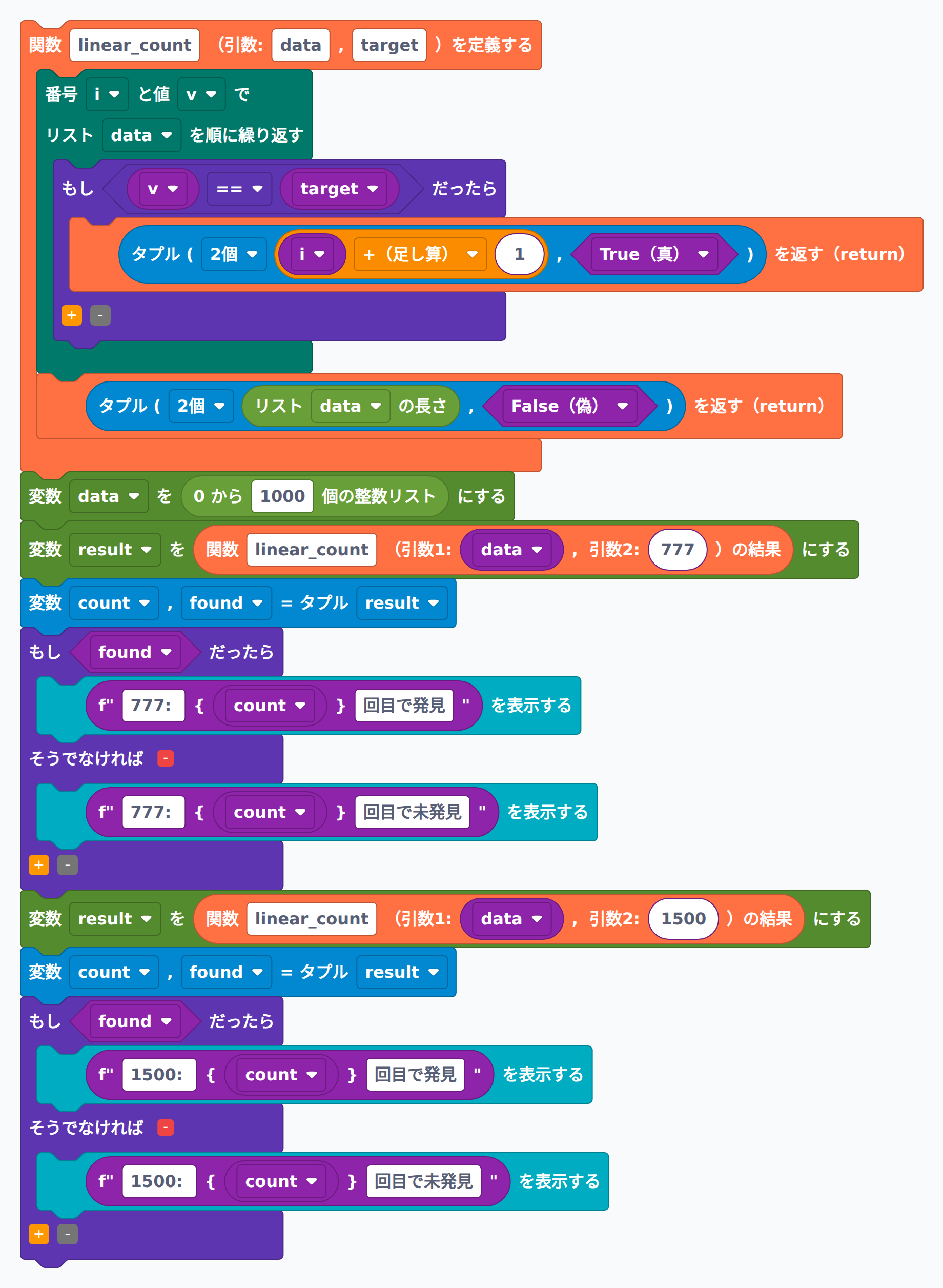
def linear_count(data, target):
for i, v in enumerate(data):
if v == target:
return i + 1, True
return len(data), False
data = list(range(1000))
count, found = linear_count(data, 777)
print(f"777: {count}回目で{'発見' if found else '未発見'}")
count, found = linear_count(data, 1500)
print(f"1500: {count}回目で{'発見' if found else '未発見'}")
解説: linear_count はタプル (比較回数, 見つかったかどうか) を返すので、呼び出し側で count, found = ... と書くと2つの値を一度に受け取れます。実行結果を見ると、値 777 はインデックス 777 にあるので 778 回目の比較で発見、値 1500 は含まれていないので全 1000 件を調べて未発見、となります。データ数が増えるほど比較回数も増える――これが O(n) の実感です。
まとめ
- 線形探索は先頭から順に比較する、最もシンプルな探索アルゴリズムです。
- ソートされていないデータにも使えます。
- 計算量は O(n):データが n 個のとき最大 n 回の比較が必要です。
- Python の
in演算子・list.index()も内部で線形探索を使っています。 - 番兵法を使うと、ループ内の終了条件チェックを減らすことができます。