
前回はこちら

Pi Cameraで撮影した画像をWebページに表示するところまで行いました。
今回はその続きとして、Pythonの強力な画像処理ライブラリ OpenCV を使い、
以下の処理を実際に体験していきます
- Pi Camera で撮影した画像を Python で読み込む
- 画像をグレースケールに変換する
- 二値化(白と黒だけの画像)を行う
- エッジ検出(輪郭を抽出)を行う
- 加工結果をウィンドウで表示する
これらは画像認識の基礎となる重要な処理です。
例えば物体検出や形状認識などは、これらの前処理を組み合わせて行われます。

OpenCVのインストール
OpenCV(Open Source Computer Vision Library) は、
カメラ画像や写真、動画をコンピュータで処理・解析するための非常に有名なライブラリです。
- OpenCVは「画像を数値の配列(=行列)」として扱います。
- 画像処理・物体検出・顔認識・特徴抽出など、幅広い分野で使われています。
- 研究だけでなく、ロボット制御、監視カメラ、スマホアプリなどにも実用例がたくさんあります。
Python では cv2 という名前で利用します。
aspberry Pi 5 には標準では OpenCV が入っていません。
まずは一度だけ、ターミナルで以下のコマンドを実行してインストールします
sudo apt update
sudo apt install -y python3-opencvインストールが完了したら、Thonnyで以下を実行して正しくインポートできるか確認しましょう
import cv2
print("OpenCV version:", cv2.__version__)エラーが出ずにバージョンが表示されればOKです。
OpenCVでカメラ映像を表示する
まずは Pi Camera で写真を撮影し、それを OpenCV で読み込んで表示してみます。
opencv_test.py
# Raspberry Pi でカメラ映像を表示・保存するプログラム
# Picamera2 + OpenCV
from picamera2 import Picamera2
import cv2
def main():
# カメラを初期化(640x480でプレビュー)
cam = Picamera2()
cam.configure(cam.create_preview_configuration(main={"size": (640, 480)}))
cam.start()
# デジタルズームを解除(センサー全体を使用)
try:
sw, sh = cam.camera_properties["PixelArraySize"]
cam.set_controls({"ScalerCrop": (0, 0, int(sw), int(sh))})
except Exception:
cam.set_controls({"ScalerCrop": (0, 0, 2592, 1944)})
while True:
# カメラ画像を取得(RGB→BGRに変換)
frame = cv2.cvtColor(cam.capture_array(), cv2.COLOR_RGB2BGR)
# そのまま表示
cv2.imshow("Camera", frame)
key = cv2.waitKey(1) & 0xFF
if key == ord('s'): # sキーで保存
cv2.imwrite("frame.jpg", frame)
print("Saved: frame.jpg")
elif key == ord('q'): # qキーで終了
break
# 終了処理
cv2.destroyAllWindows()
cam.stop()
if __name__ == "__main__":
main()PiCamera2 → RGB
OpenCV → BGR
この2つの色順の違いに注意しましょう。変換には cv2.cvtColor() を使います。

グレースケール変換をしてみよう
カラー画像はRGB(赤・緑・青)の3チャンネルで構成されています。
一方、グレースケール画像は1チャンネルで明るさだけを表します。
画像処理では、このグレースケールに変換することでデータを簡素化し、処理を軽くすることが多いです。
# Raspberry Pi カメラ映像をカラー+グレースケール表示
# Picamera2 + OpenCV
from picamera2 import Picamera2
import cv2
def main():
# カメラ初期化(640x480)
cam = Picamera2()
cam.configure(cam.create_preview_configuration(main={"size": (640, 480)}))
cam.start()
# デジタルズーム解除(センサー全体を使用)
try:
sw, sh = cam.camera_properties["PixelArraySize"]
cam.set_controls({"ScalerCrop": (0, 0, int(sw), int(sh))})
except Exception:
cam.set_controls({"ScalerCrop": (0, 0, 2592, 1944)})
while True:
# RGB → BGR
frame = cv2.cvtColor(cam.capture_array(), cv2.COLOR_RGB2BGR)
# グレースケール変換
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 表示(カラー / グレー)
cv2.imshow("Color", frame)
cv2.imshow("Gray", gray)
key = cv2.waitKey(1) & 0xFF
if key == ord('s'): # 保存
cv2.imwrite("frame_color.jpg", frame)
cv2.imwrite("frame_gray.jpg", gray)
print("Saved.")
elif key == ord('q'): # 終了
break
# 終了処理
cv2.destroyAllWindows()
cam.stop()
if __name__ == "__main__":
main()カラー画像に比べて、白黒のシンプルな画像が表示されます。
これは OpenCV が内部で各ピクセルの明るさを計算して変換しています。

二値化(しきい値処理)
グレースケール画像をさらに単純化したものが「二値化」です。
指定した「しきい値」を境にして、ピクセルを「白」または「黒」に振り分けます。
- 明るさ ≥ しきい値 → 白(255)
- 明るさ < しきい値 → 黒(0)
しきい値の処理にはいくつかあります。
| 方法 | 特徴 |
|---|---|
| 手動しきい値 | 自分で値を決める(簡単だが環境依存) |
| Otsu(二値化+大津の手法) | 画像のヒストグラムから自動で最適なしきい値を決める |
| 適応的しきい値 | 明暗ムラや影がある環境に強い。周囲の明るさを見て局所的に判断する |
3種類の処理方法を以下のコードで比べてみます。
# Raspberry Pi カメラ映像を3種類の二値化で表示・保存
# Picamera2 + OpenCV
from picamera2 import Picamera2
import cv2
def nothing(x):
pass
def main():
# カメラ初期化(640x480)
cam = Picamera2()
cam.configure(cam.create_preview_configuration(main={"size": (640, 480)}))
cam.start()
# デジタルズーム解除
try:
sw, sh = cam.camera_properties["PixelArraySize"]
cam.set_controls({"ScalerCrop": (0, 0, int(sw), int(sh))})
except Exception:
cam.set_controls({"ScalerCrop": (0, 0, 2592, 1944)})
# スライダーウィンドウ(手動しきい値用)
cv2.namedWindow("Controls")
cv2.createTrackbar("Manual TH", "Controls", 128, 255, nothing)
while True:
# カメラ画像(RGB→BGR)
frame = cv2.cvtColor(cam.capture_array(), cv2.COLOR_RGB2BGR)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 手動しきい値
th = cv2.getTrackbarPos("Manual TH", "Controls")
_, bin_manual = cv2.threshold(gray, th, 255, cv2.THRESH_BINARY)
# Otsu(二値化+自動しきい値)
_, bin_otsu = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# 適応的二値化(局所的に判定)
bin_adp = cv2.adaptiveThreshold(
gray, 255,
cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
cv2.THRESH_BINARY,
11, 2
)
# 表示
cv2.imshow("Original", frame)
cv2.imshow("Manual", bin_manual)
cv2.imshow("Otsu", bin_otsu)
cv2.imshow("Adaptive", bin_adp)
key = cv2.waitKey(1) & 0xFF
if key == ord('s'): # 保存
cv2.imwrite("bin_manual.jpg", bin_manual)
cv2.imwrite("bin_otsu.jpg", bin_otsu)
cv2.imwrite("bin_adaptive.jpg", bin_adp)
print("Saved.")
elif key == ord('q'): # 終了
break
cv2.destroyAllWindows()
cam.stop()
if __name__ == "__main__":
main()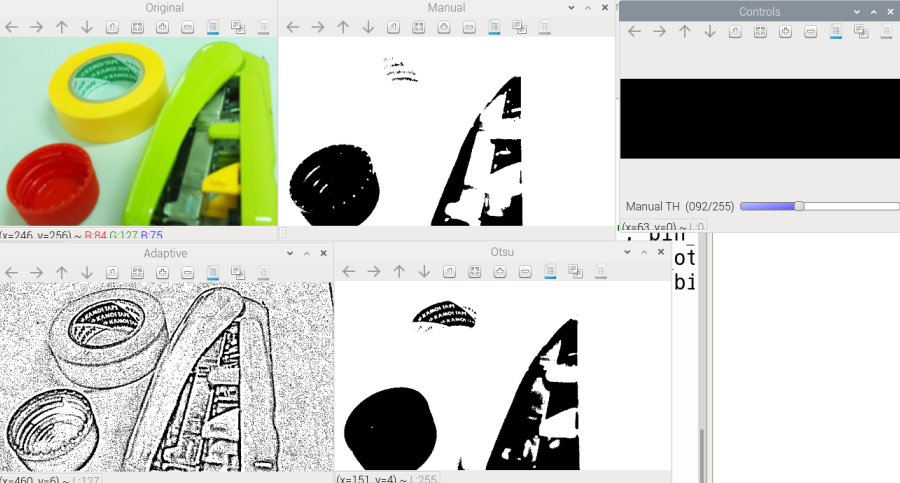
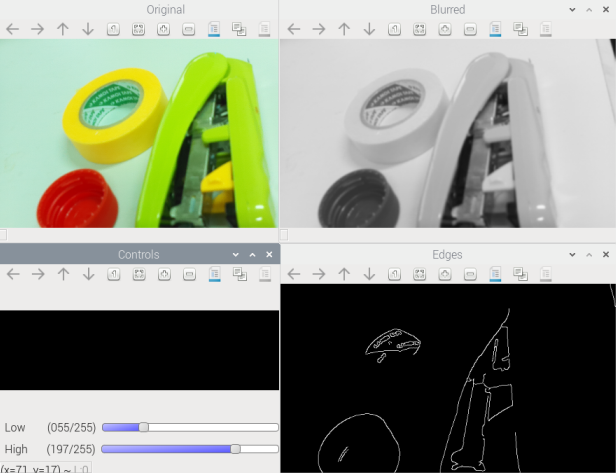
エッジ検出(輪郭抽出)
エッジとは
エッジとは、画像の中で明るさが急に変わる「境界線」のことです。
エッジ検出は、物体の輪郭を見つけるための基本的な手法です。
Canny法の流れ(4ステップ)
- ノイズ除去(ガウシアンぼかし)
- 勾配(明るさの変化)を計算
- 細線化
- 二つのしきい値によるヒステリシス処理(弱いエッジをつなぐ)
# Raspberry Pi カメラ映像で Canny エッジ検出
# Picamera2 + OpenCV
from picamera2 import Picamera2
import cv2
def nothing(x):
pass
def main():
# カメラ初期化(640x480)
cam = Picamera2()
cam.configure(cam.create_preview_configuration(main={"size": (640, 480)}))
cam.start()
# デジタルズーム解除(フル視野)
try:
sw, sh = cam.camera_properties["PixelArraySize"]
cam.set_controls({"ScalerCrop": (0, 0, int(sw), int(sh))})
except Exception:
cam.set_controls({"ScalerCrop": (0, 0, 2592, 1944)})
# Canny パラメータ設定用スライダー
cv2.namedWindow("Controls")
cv2.createTrackbar("Low", "Controls", 50, 255, nothing)
cv2.createTrackbar("High", "Controls", 150, 255, nothing)
while True:
# カメラ画像(RGB→BGR)
frame = cv2.cvtColor(cam.capture_array(), cv2.COLOR_RGB2BGR)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# ぼかし(ノイズ低減)
blur = cv2.GaussianBlur(gray, (5, 5), 1.0)
# Trackbar の値を取得
low = cv2.getTrackbarPos("Low", "Controls")
high = cv2.getTrackbarPos("High", "Controls")
high = max(high, low + 1) # High は Low より大きく
# Canny エッジ検出
edges = cv2.Canny(blur, low, high)
# 表示
cv2.imshow("Original", frame)
cv2.imshow("Blurred", blur)
cv2.imshow("Edges", edges)
key = cv2.waitKey(1) & 0xFF
if key == ord('q'): # 終了
break
cv2.destroyAllWindows()
cam.stop()
if __name__ == "__main__":
main()画像の輪郭部分だけが白い線で抽出されて表示されます。
この処理は、ロボットビジョンや物体検出の基本中の基本です。
問題7
カメラで撮影した映像に白い物体(例えば白いブロックや紙切れ)が映っているとします。
このとき、画像処理を使って「白い物体がいくつあるか」自動で数えるプログラムを作ってください。
条件
- Raspberry Pi 5 とカメラ(640×360)を使用する
- OpenCV を使って画像処理を行う
- 影や明るさのムラがあっても正しく数えられるようにする
- 画面上に「検出結果(赤い枠)」と「数」を表示する
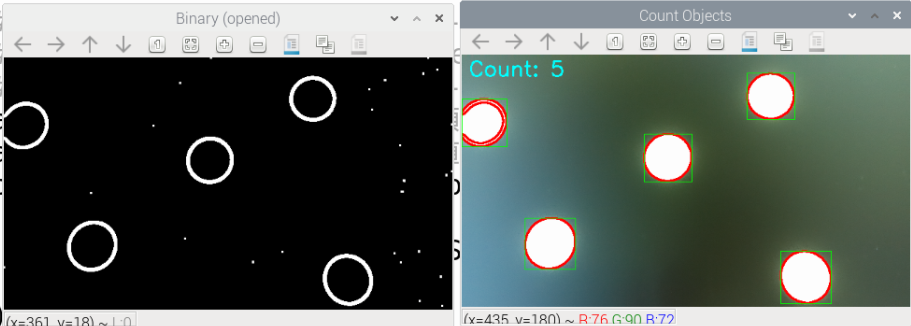
たとえば下のようなシーンを想定します
| カメラ画像例 | 二値化+輪郭抽出例 |
|---|---|
| 白い紙の上に白いブロック | 白い物体に赤い枠、個数が数えられている |
この課題を解くためには、第2回で学んだ以下の処理を組み合わせることがポイントです
| 技術 | 目的 | 関数 |
|---|---|---|
| グレースケール変換 | カラーを明るさ情報だけにする | cv2.cvtColor |
| 平滑化(ぼかし) | ノイズを減らして処理を安定させる | cv2.GaussianBlur |
| 適応的二値化 | 照明ムラや影に強く白と黒に分ける | cv2.adaptiveThreshold |
| 形態学的処理(オープニング) | 小さなノイズを消す | cv2.morphologyEx |
| 輪郭抽出 | 白い物体を検出する | cv2.findContours |
| 面積フィルタ+描画 | 小さいノイズを除外、結果をわかりやすく表示 | cv2.contourArea, cv2.drawContours, cv2.boundingRect |
ヒント1:
カメラ画像をグレースケール化 → 適応的二値化してみてください。
→ 白い物体が白、背景が黒になるように調整。
※なぜ「適応的二値化」を使うのか?
普通のしきい値(128など)だと、影や光のムラで一部が黒くなって検出漏れが出ることがあります。
一方、適応的二値化は「周囲の明るさを見て」しきい値を決めるので、照明が均一でなくても安定して対象物を抽出できます。
ヒント2:
二値化結果に小さなノイズが残る場合は、
GaussianBlur()で事前にぼかす- または
morphologyEx(..., MORPH_OPEN)で小さいゴミを消す
→ 二値画像がきれいになると輪郭抽出の精度が上がる。
※ぼかし(GaussianBlur)や形態学的処理(オープニング)を加えると、検出漏れや誤カウントがぐっと減ります。
二値化だけで輪郭を取ると、小さいゴミが大量に数えられてしまうことが多いので注意です。
ヒント3:
cv2.findContours() で輪郭を抽出しよう。
小さなノイズまでカウントしないように、cv2.contourArea() で面積をチェックして除外する。
輪郭を取ったあと、小さい面積の輪郭を無視することで誤検出を防ぎます。
これはロボットビジョンでも非常によく使われる基本テクニックです。
ヒント4:
cv2.drawContours() や cv2.rectangle() で検出結果を可視化し、cv2.putText() で物体数を画面に表示するとわかりやすい。
画像認識用のモデルは必要に応じて以下の画像をダウンロードし、画面に表示させ、それをカメラで読み込むなどして対応してください。

うまく認識できれば以下のようになります。
回答例はこちら
# 適応的二値化 → ノイズ除去 → 輪郭抽出
# Picamera2 + OpenCV
from picamera2 import Picamera2
import cv2, numpy as np, time
def main():
# カメラ初期化(プレビュー解像度 640x480)
cam = Picamera2()
cam.configure(cam.create_preview_configuration(main={"size": (640, 480)}))
cam.start()
time.sleep(0.2) # 起動安定待ち
# フル視野を使う(デジタルズームを無効化)
try:
sw, sh = cam.camera_properties["PixelArraySize"]
cam.set_controls({"ScalerCrop": (0, 0, int(sw), int(sh))})
except:
cam.set_controls({"ScalerCrop": (0, 0, 2592, 1944)})
min_area = 50 # 小さすぎる輪郭は無視
max_area = 30000 # 外枠など大きすぎる輪郭を除外
while True:
# カメラ画像を取得し,RGB→BGR→GRAY へ変換
frame = cv2.cvtColor(cam.capture_array(), cv2.COLOR_RGB2BGR)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# GaussianBlurでノイズ軽減
blur = cv2.GaussianBlur(gray, (5, 5), 1.0)
# 適応的二値化(背景が明確なら C=0 で良好)
binary = cv2.adaptiveThreshold(
blur, 255,
cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
cv2.THRESH_BINARY,
11, 0
)
# 小さなノイズを除去(開演算)
opened = cv2.morphologyEx(
binary, cv2.MORPH_OPEN,
np.ones((3, 3), np.uint8), iterations=1
)
# 最外輪郭のみ抽出
contours, _ = cv2.findContours(
opened, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE
)
vis = frame.copy()
count = 0
# 面積でフィルタし,対象のみ描画
for c in contours:
area = cv2.contourArea(c)
if area < min_area or area > max_area:
continue
count += 1
cv2.drawContours(vis, [c], -1, (0, 0, 255), 2) # 輪郭(赤)
x, y, w, h = cv2.boundingRect(c)
cv2.rectangle(vis, (x, y), (x+w, y+h), (0,255,0),1) # 矩形(緑)
# 個数表示
cv2.putText(
vis, f"Count: {count}", (10,30),
cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255,255,0), 2
)
# 結果表示
cv2.imshow("Binary", opened)
cv2.imshow("Contours", vis)
# q で終了
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
cam.stop()
if __name__ == "__main__":
main()うまくできた場合は様々な背景の色で自然に白色の物体が検出できるように考えてみてください。
ほかの色の物体を検出するにはどうしたらよいでしょうか?
考えてみてください。
次回はこちら

Follow me!