
前回はk-NN を使って
- 特徴(ピクセル値)を自分で作る
- それをAIに覚えさせて分類する
という「古典的な画像認識」を体験しました。
今回は、
ディープラーニング(深層学習) を使った現代のAIが
どのように“自動で特徴を学ぶ”のかを学びます。


古典的画像認識とディープラーニングの違い
- 古典的手法(k-NN / SVM / 画像処理)
[人間]が特徴を作る(エッジ・明るさ・図形など)
↓
[AI]が分類だけする
- ディープラーニング
[AI]が特徴を自動で学習する
↓
[AI]が分類も自動で行う
ここが最大の違いです
ディープラーニングとは?
ディープラーニングは
「多層構造のニューラルネットワークを大量のデータで学習させる方法」
のことです。
イメージとしては
人間の脳を“ゆるく模倣”した仕組みです。
- 脳には神経細胞(ニューロン)が多数存在する
- 入力 → 加工 → 出力 の流れで情報処理している
ディープラーニングでは、これを数学的に再現します。
ニューラルネットワークの基本
“ニューロン(Neuron)”とは数学でいうと、これはただの計算機です。
入力 → 重みをかける → 合計する → 活性化関数で出力
例:
あなたの作品(図形)を分類するとき、
人間ならこんな感じの判断をします。
- 円っぽい?
- 角がある?
- 細長い?
- 面積は広い?狭い?
ニューラルネットも同じように、
たくさんの“観点(特徴)”を同時に考えます。
ニューラルネットの構造
ニューラルネットは通常この3つで構成されています:
[入力層] → [隠れ層 × n] → [出力層]
■ 入力層
画像のピクセル値などが入る(特徴量)
■ 隠れ層
特徴を組み合わせたり、より抽象化した特徴を作る場所
例:
- 階層1:エッジ
- 階層2:丸っぽさ、角っぽさ
- 階層3:形の特徴
- …
■ 出力層
分類結果(circle / square / triangle など)
CNN(畳み込みニューラルネットワーク)は画像に最適
画像処理に強いディープラーニングといえば CNN(Convolutional Neural Network)。
CNN の特徴:
- 画像の「局所的な特徴」を捉える(目、鼻、角、丸みなど)
- 位置が少し変わっても認識できる(平行移動に強い)
- 背景の変化に強い(k-NNとの大きな違い)
- データ数があるほど性能が爆発的に向上
CNNが何をしているか(ざっくり)
画像 → 畳み込み(特徴抽出) → プーリング(縮小) → 全結合(分類)
CNNは「特徴量を自動で作る」
これは、前回の k-NN で人が行ったこと
(ROI切り出し / Canny / 明暗調整)を AI自身が担当するということです。
なぜディープラーニングが強いのか?
近年多くの画像処理にはこちらのディープラーニングが使用されています。
ディープラーニングコンテストなんかも開催されるくらいです。
以下のような理由が挙げられます。
✔ 特徴を「作る」のがうますぎる
人間が思いつかない特徴でも学習する
✔ ノイズに強い
背景・明るさの違いなどに強い(k-NNの弱点を克服)
✔ データが増えるほどますます強くなる
大量データ向き
✔ 一度学習すれば推論が高速
リアルタイム認識向き(Raspberry Piでも可能)
CNNの仕組み
Raspberry Pi でも動く 「軽量CNN」 を使って、
前回認識した circle / square / triangle を分類してみます。
CNNとは何か?
CNN(Convolutional Neural Network)は
画像認識に特化したディープラーニングのモデル です。
普通のニューラルネットは:
- 画像を「1次元ベクトル(flatten)」にする必要がある
- 画像の構造(縦線・横線・角など)をうまく活かせない
という弱点がありました。
CNN はこれを克服し、
画像の中の“局所的な特徴”を自動で学習できる
という非常に強力な特徴を持っています。
CNN はどうやって画像を理解するのか?
CNN はこんな流れで画像を理解します。
画像 → 畳み込み(特徴抽出) → 活性化 → プーリング(縮小)
→ 畳み込み → プーリング → … → 全結合(分類)
畳み込み(Convolution)とは
「画像の上を小さなフィルタがスキャンして特徴を抽出する」処理。
たとえば 3×3 のフィルタが画像を走査して、
「縦線」「横線」「角」などの特徴を見つけます。
入力画像(5×5):
1 1 1 0 0
1 1 1 0 0
1 1 1 0 0
0 0 0 1 1
0 0 0 1 1
縦線フィルタ(3×3):
1 0 -1
1 0 -1
1 0 -1
畳み込み結果(特徴マップ):
3 3 -3 ...
3 3 -3 ...
...フィルタが画像をなぞることで、
縦線がある場所だけ強い反応(大きな値)を出します。
畳み込みは以下のような特徴があります。
✔ 隣り合うピクセルの関係を保ったまま処理できる
→ エッジや模様を自然に捉えられる
✔ 同じフィルタを全領域に適用する(重み共有)
→ 計算量が少ない、学習が安定
✔ 画像が平行移動しても検出できる
→ 図形の位置が変わっても強い
プーリング(Pooling)とは?
畳み込みの後は、次の処理を行います
「特徴をまとめて画像サイズを小さくする」
- ノイズを減らす
- 計算量を減らす
- 特徴を安定させる
よく使うのが Max Pooling(最大値プーリング)。
例:
入力(2×2の領域):
1 3
2 8
MaxPooling → 8(最大値)画像全体を4分の1や1/9に縮小していきます。
CNNの階層が深いほど何が起こるか
例:あなたの「◯、□、△」図形の場合
1層目:エッジを発見
- 横線
- 縦線
- 斜め線
2層目:形状のパーツを発見
- 角
- 曲線
- 面
3層目:形の全体像を理解
- 円の輪郭
- 四角の枠
- 三角の頂点構造
最終層
- これは circle
- これは square
という判定ができるようになります。
これが CNN の最大の強み:
特徴を自動で積み上げて、抽象的な概念を学習する。
前回学習した機械学習と比較すると以下のようにまとめられます。
| 課題 | k-NN | CNN |
|---|---|---|
| 背景の違いに弱い | × | ◎(特徴を自動抽出) |
| 回転・位置ズレに弱い | × | ◎ |
| データ量が増えると強い | △ | ◎◎ |
| 手動特徴量が必要 | ○ | 不要(自動学習) |
| 処理速度 | 遅い | 速い(推論) |
CNN の全体構造
今回は以下のようなフローで処理を行ってみます。
入力 (32×32 gray)
↓
Conv2D(3×3×8フィルタ)
↓
ReLU
↓
MaxPooling(2×2)
↓
Conv2D(3×3×16)
↓
ReLU
↓
MaxPooling(2×2)
↓
Flatten(1次元化)
↓
Dense(全結合)
↓
出力(3クラス:circle/square/triangle)学習モデルの作成
学習データの作成は処理が重たく、Raspberry Piでは少々非力です。
今回は学習のみ各自Windows PCで行い、学習データを持ってきてRasPiで検出させてみましょう。
PC側でThonnyを開きます。
右下の実行環境をローカルPython3にします。
ツール → パッケージの管理
tensorflowをインストールします。
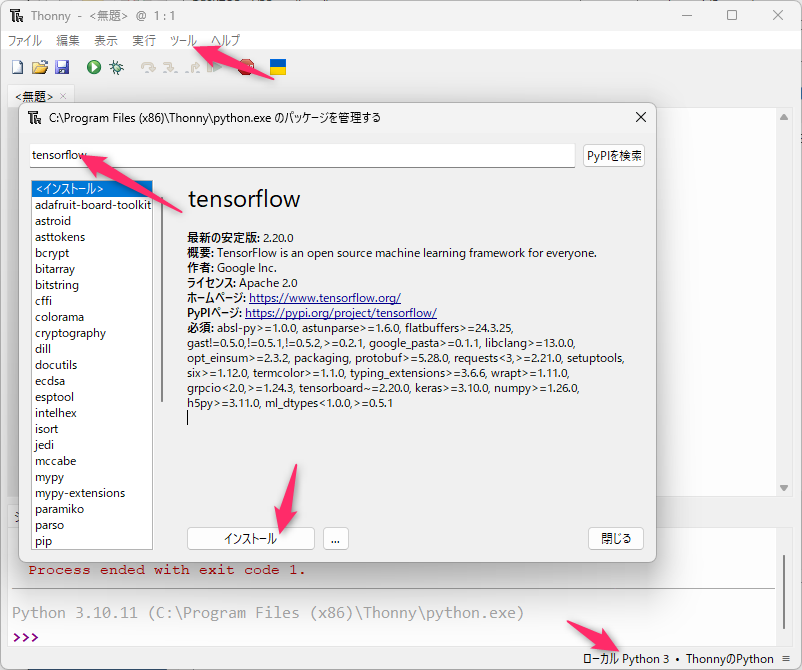
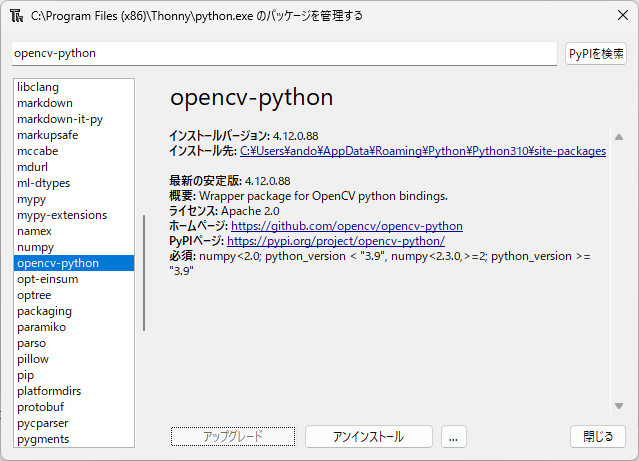
同様にopencv-pythonもインストールします。
前回作成したデータセットを使って学習してみましょう。
少々手間ですが、前回作成したdatasetをフォルダ事RasPi5からデータを持ってきます。
同じフォルダ上に以下のPythonスクリプトを作成します。

train_cnn.py
準備ができたらスクリプトを実行します。
import tensorflow as tf
import numpy as np
import os
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import layers, models
# ====== 1. 画像が入っているフォルダ ======
DATASET_DIR = "dataset" # 前回作成済み
# ====== 2. データ読み込み(ImageDataGenerator) ======
datagen = ImageDataGenerator(
rescale=1.0/255,
validation_split=0.2 # 訓練80% / テスト20%
)
# 訓練データ
train_data = datagen.flow_from_directory(
DATASET_DIR,
target_size=(64, 64), # CNN入力サイズ
batch_size=8,
class_mode='categorical',
subset='training'
)
# 検証データ
val_data = datagen.flow_from_directory(
DATASET_DIR,
target_size=(64, 64),
batch_size=8,
class_mode='categorical',
subset='validation'
)
# クラス名確認
print("クラス名(ラベル):", train_data.class_indices)
# ====== 3. CNNモデル定義(小さめシンプル構造) ======
model = models.Sequential([
layers.Conv2D(16, (3,3), activation='relu', input_shape=(64,64,3)),
layers.MaxPooling2D(2,2),
layers.Conv2D(32, (3,3), activation='relu'),
layers.MaxPooling2D(2,2),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(3, activation='softmax') # circle / square / triangle
])
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)
model.summary()
# ====== 4. 学習 ======
history = model.fit(
train_data,
epochs=10,
validation_data=val_data
)
# ====== 5. 学習済みモデル保存 ======
model.save("shape_cnn.h5")
print("shape_cnn.h5 を保存しました!")
# ====== 6. TFLite 変換(PC側のみ成功します) ======
converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()
with open("shape_cnn.tflite", "wb") as f:
f.write(tflite_model)
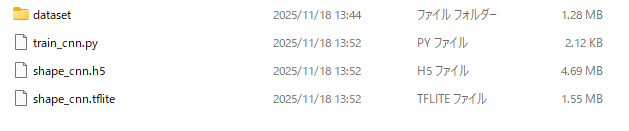
print("shape_cnn.tflite を作成しました!")実行が終わると以下のように学習ファイルが生成されます。
処理の流れ
ざっくり言うと、以下の順で処理を行っています。
dataset/フォルダから、circle/square/triangle の画像を読み込む- 画像を 64×64 に揃えて、0〜1に正規化しながらミニバッチで供給
- CNN(畳み込みニューラルネットワーク)を定義
- 何回も学習して、「この画像はどのクラスか」を当てられるようにする
- 学習済みモデルを
shape_cnn.h5とshape_cnn.tfliteに保存
1. データ読み込み部分
import tensorflow as tf
import numpy as np
import os
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import layers, models
DATASET_DIR = "dataset"ImageDataGenerator
→ フォルダの中の画像を、自動で読み込み&リサイズ&正規化までやってくれる便利クラスです。
datagen = ImageDataGenerator(
rescale=1.0/255,
validation_split=0.2
)rescale=1.0/255
→ 画像のピクセル値(0〜255)を 0〜1 に割り算。
ニューラルネットが扱いやすいスケールに揃えます。
validation_split=0.2
→ データの 20% を「テスト用(検証用)」として取り分ける設定です。
train_data = datagen.flow_from_directory(
DATASET_DIR,
target_size=(64, 64),
batch_size=8,
class_mode='categorical',
subset='training'
)
val_data = datagen.flow_from_directory(
DATASET_DIR,
target_size=(64, 64),
batch_size=8,
class_mode='categorical',
subset='validation'
)flow_from_directory
→ dataset/circle, dataset/square, dataset/triangle のような
フォルダ構造を見て自動でラベルをつけてくれる。
target_size=(64, 64)
→ すべての画像を 64×64 にリサイズしてからモデルに渡す。
subset='training' / 'validation'
→ さっきの validation_split=0.2 のおかげで
80% → train、20% → validation に自動で分かれます。
print("クラス名(ラベル):", train_data.class_indices){'circle': 0, 'square': 1, 'triangle': 2} のように
フォルダ名 → クラス番号 の対応が確認できます。
→ 後で Pi 側で CLASS_NAMES を決めるとき、この順番と揃えるのが大事です。
2. CNNモデルの定義
model = models.Sequential([
layers.Conv2D(16, (3,3), activation='relu', input_shape=(64,64,3)),
layers.MaxPooling2D(2,2),
layers.Conv2D(32, (3,3), activation='relu'),
layers.MaxPooling2D(2,2),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(3, activation='softmax')
])Conv2D(16, (3,3))
→ 3×3 のフィルタを 16枚かける「特徴抽出フィルタ」
→ 画像のエッジや模様などの特徴を自動で学ぶ層です。
MaxPooling2D(2,2)
→ 特徴マップを 1/2 に縮める(2×2ごとに最大値を取る)。
→ 計算量を減らしつつ、位置のずれに強くします。
2回目の Conv2D/MaxPooling で、より抽象的な特徴(形のパターンなど)を学びます。
Flatten()
→ 2次元の画像特徴を1次元ベクトルにピロッと伸ばす。
Dense(64, activation='relu')
→ 全結合層。抽出された特徴から「これはどのクラスっぽいか」を考える部分。
Dense(3, activation='softmax')
→ 最後の出力(3クラスの確率)。
例: [0.9, 0.05, 0.05] なら「ほぼ circle」。
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)optimizer='adam'
→ 重みの調整アルゴリズム(最適化手法)。今は「そういうもの」と理解でOK。
loss='categorical_crossentropy'
→ 多クラス分類用の誤差関数。「正解とのズレ」を数値化。
metrics=['accuracy']
→ 学習中に「正解率」を表示します。
3.学習と保存
history = model.fit(
train_data,
epochs=10,
validation_data=val_data
)epochs=10
→ 全データを 10 回繰り返し学習。
毎エポックごとに
accuracy(訓練データの正解率)val_accuracy(検証データの正解率)
が出て、**「ちゃんと汎化できているか」**が見えます。
model.save("shape_cnn.h5")
print("shape_cnn.h5 を保存しました!")Keras形式(.h5)で保存。
→ PCで再学習したり可視化するときに使えます。
converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()
with open("shape_cnn.tflite", "wb") as f:
f.write(tflite_model)ここが 推論用(Raspberry Pi用)のモデルに変換している部分。
.tflite は軽くて速い、「実行専用の小さなモデル」だと思ってOKです。
画像の推論
ここからはRaspi5で戻ります。
Raspi5のターミナルで以下のコマンドを実行します。
pip3 install --break-system-packages tflite-runtime
以下のスクリプトを作成します。
classify_cnn_cam.py
同じフォルダに先ほどPCで作った学習ファイル、shape_cnn.tfliteを置いて、実行します。
from picamera2 import Picamera2
import cv2
import numpy as np
import tflite_runtime.interpreter as tflite
import time
# ===== 1. TFLite モデルの読み込み =====
MODEL_PATH = "shape_cnn.tflite"
interpreter = tflite.Interpreter(model_path=MODEL_PATH)
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# 学習時のクラス名(PC側の train_cnn.py と対応)
CLASS_NAMES = ["circle", "square", "triangle"]
def main():
# カメラ初期化
cam = Picamera2()
cam.configure(cam.create_preview_configuration(main={"size": (640, 480)}))
cam.start()
# デジタルズームを解除
try:
sw, sh = cam.camera_properties["PixelArraySize"]
cam.set_controls({"ScalerCrop": (0, 0, int(sw), int(sh))})
except Exception:
# うまく取得できない場合は、OV5647 の典型的なフル解像度を指定
cam.set_controls({"ScalerCrop": (0, 0, 2592, 1944)})
print("q:終了")
while True:
# カメラ画像を取得(RGB→BGR)
frame = cv2.cvtColor(cam.capture_array(), cv2.COLOR_RGB2BGR)
h, w, _ = frame.shape
# 画面中央にガイド枠(ここだけを分類に使う)
gx1, gy1 = w // 4, h // 4
gx2, gy2 = w * 3 // 4, h * 3 // 4
cv2.rectangle(frame, (gx1, gy1), (gx2, gy2), (0, 255, 255), 2)
cv2.putText(frame, "Put object inside box",
(10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 255), 2)
# ガイド枠内の画像を切り出し
roi = frame[gy1:gy2, gx1:gx2]
#CNN入力用に前処理
# 64x64 にリサイズ(学習時と同じサイズ)
img = cv2.resize(roi, (64, 64))
# 0〜1に正規化
img = img.astype(np.float32) / 255.0
# (1, 64, 64, 3) に形を揃える
img = np.expand_dims(img, axis=0)
#TFLite 推論
interpreter.set_tensor(input_details[0]["index"], img)
interpreter.invoke()
output = interpreter.get_tensor(output_details[0]["index"])[0]
pred_id = int(np.argmax(output))
label = CLASS_NAMES[pred_id]
prob = float(output[pred_id])
# 結果を画面左上に表示
cv2.putText(frame, f"{label} ({prob:.2f})",
(10, 70), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 0), 2)
# そのまま表示
cv2.imshow("CNN Camera", frame)
key = cv2.waitKey(1) & 0xFF
if key == ord("q"):
break
# ===== 8. 終了処理 =====
cv2.destroyAllWindows()
cam.stop()
if __name__ == "__main__":
main()うまく認識できていれば以下のように判別できます。
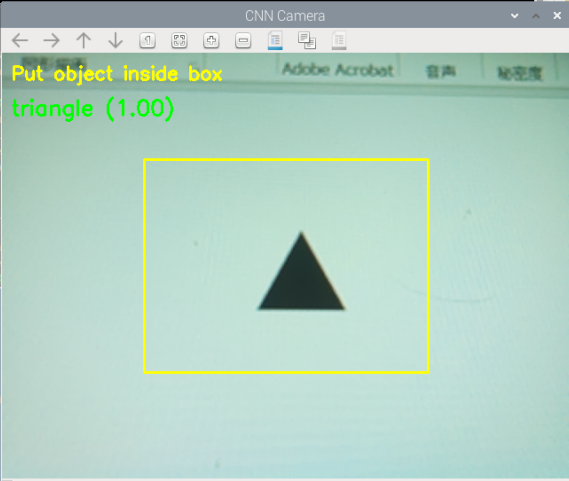
処理の流れ
shape_cnn.tfliteを読み込む(TFLiteインタプリタを用意)- PiCameraを起動し、デジタルズームを解除してプレビュー
- 毎フレーム:
- 画像を取得
- 中央のガイド枠だけ切り出し
- 64×64にリサイズ&0〜1に正規化
- モデルで推論
- 結果(ラベル+確率)を画面に描画
qキーが押されたら終了
1.ライブラリとモデル読み込み
from picamera2 import Picamera2
import cv2
import numpy as np
import tflite_runtime.interpreter as tflite
import time
MODEL_PATH = "shape_cnn.tflite"
interpreter = tflite.Interpreter(model_path=MODEL_PATH)
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
CLASS_NAMES = ["circle", "square", "triangle"]tflite_runtime.interpreter as tflite
→ Raspberry Piでは TensorFlow 本体ではなく、軽量な TFLite Runtime を使用。
interpreter.allocate_tensors()
→ TFLite の準備(メモリ確保)。
input_details / output_details
→
- 入力テンソルの形(例:
(1, 64, 64, 3)) - 出力テンソルの形(例:
(1, 3))
などを取得しています。
CLASS_NAMES
→ 学習時のクラス順に対応するラベル。
(ここを間違えると「circleなのにsquareと表示」みたいなことになります)
2.カメラ初期化とデジタルズーム解除
cam = Picamera2()
cam.configure(cam.create_preview_configuration(main={"size": (640, 480)}))
cam.start()
try:
sw, sh = cam.camera_properties["PixelArraySize"]
cam.set_controls({"ScalerCrop": (0, 0, int(sw), int(sh))})
except Exception:
cam.set_controls({"ScalerCrop": (0, 0, 2592, 1944)})create_preview_configuration(main={"size": (640, 480)})
→ 表示用の解像度を 640×480 に設定。
PixelArraySize
→ センサー本来の解像度(例:2592×1944)。
ScalerCrop にフルサイズを指定
→ ズームを解除して、センサー全体を使う設定。
これをしないと「変に拡大された映像」になります。
3.メインループ:画像取得〜前処理
frame = cv2.cvtColor(cam.capture_array(), cv2.COLOR_RGB2BGR)
h, w, _ = frame.shape
gx1, gy1 = w // 4, h // 4
gx2, gy2 = w * 3 // 4, h * 3 // 4
cv2.rectangle(frame, (gx1, gy1), (gx2, gy2), (0, 255, 255), 2)
cv2.putText(frame, "Put object inside box",
(10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 255), 2)
roi = frame[gy1:gy2, gx1:gx2]cam.capture_array()
→ PiCamera から1フレーム取得(RGB)。
cv2.cvtColor(..., cv2.COLOR_RGB2BGR)
→ OpenCVはBGR想定なので変換。
中央にガイド枠(黄色い四角)を描画し、
その中だけを roi として切り出しています。
→ 分類に使うのはこの部分だけ。
img = cv2.resize(roi, (64, 64))
img = img.astype(np.float32) / 255.0
img = np.expand_dims(img, axis=0)64×64 にリサイズ
→ 学習時と同じ入力サイズに揃えることが非常に重要。
0〜1 に正規化
→ 学習時も rescale=1.0/255 していたので、同じ前処理に合わせる必要があります。
np.expand_dims(..., axis=0)
→ (64,64,3) → (1,64,64,3) に変換。
TFLiteモデルは「バッチ次元つき」を期待しています。
4.推論(インタプリタを使う)
interpreter.set_tensor(input_details[0]["index"], img)
interpreter.invoke()
output = interpreter.get_tensor(output_details[0]["index"])[0]set_tensor
→ 入力テンソル(indexで指定)に前処理済み画像をセット。
invoke()
→ 実際に推論を実行。
get_tensor
→ 出力(3クラスの確率ベクトル)を取得。
例: [0.1, 0.8, 0.1] なら square が一番高い。
pred_id = int(np.argmax(output))
label = CLASS_NAMES[pred_id]
prob = float(output[pred_id])np.argmax(output)
→ 一番確率が高いクラスのインデックスを取得。
CLASS_NAMES でインデックス→文字(circle/square/triangle)に変換。
prob はそのクラスの確率(0.00〜1.00)。
5.結果の表示と終了処理
cv2.putText(frame, f"{label} ({prob:.2f})",
(10, 70), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 0), 2)
cv2.imshow("CNN Camera", frame)
key = cv2.waitKey(1) & 0xFF
if key == ord("q"):
break画面左上に「square (0.92)」のように描画。
q キーでループ終了。
cv2.destroyAllWindows()
cam.stop()ウィンドウを閉じてカメラも停止。後始末です。
問題14
別の物体を学習、推論してみて実行結果を報告、考察してみてください。
まとめ
ここまで頑張れた皆さんは以下の力が身についたはずです。
- ✔ Raspberry Pi のカメラ制御
- ✔ OpenCV による基礎画像処理
- ✔ 輪郭抽出と図形認識
- ✔ CNN(機械学習)の基礎
- ✔ 学習データ収集 → PCで学習 → Piで推論 の一連の流れ
- ✔ 自作モデルでリアルタイム判定プログラムが作れる力
この経験を通じて、
「AIを使う側」ではなく
AIを自分で作る側への第一歩を確実に踏み出しました。
AI開発に興味を持った方はネット上にたくさん文献がある時代です。
どんどん学習を進めていきましょう。
Follow me!