
前回は、すでに学習済みのAIモデル(Haar Cascade)を使って「顔検出」を行いました。
しかし、そのモデルは他の誰かが大量のデータで学習させたものです。
今回は、自分の手でAIに学習をさせる体験を行います。


機械学習とは?
人間の学習との違い
私たちは「経験」から学びます。
たとえば、「丸いものを何度も見ると、丸の特徴を覚える」ように。
機械学習も同じです。
AIにたくさんの例を見せて「どんな特徴を持つものが○○なのか」を数値的に学習させます。
機械学習の流れ
① データを集める(例:円・三角・四角の画像)
② 特徴量を取り出す(例:形・明るさ・輪郭)
③ モデルを学習させる(AIがルールを作る)
④ 新しい画像を分類してみる
この一連の流れを「学習 → 推論(予測)」と呼びます。
特徴量(Feature)とは?
AIは画像をそのまま「絵」としては理解できません。
画像はコンピュータにとって「数の集まり(ピクセルの明るさ)」です。
これらの数値をもとに「似ているか・違うか」を判断します。
| 画像処理 | 機械学習的な意味 |
|---|---|
| グレースケール化 | 明るさ情報のみを抽出して処理を軽くする |
| 縮小 | 余分な情報を減らし、処理を速くする |
| flatten(平坦化) | 画像を1次元ベクトルに変換してAIに渡す |
データを集める
まずはAIが学習するための「教材(データ)」を自分で作ります。
今回は白い背景の上に描いた黒い図形(○・□・△)を例にします。
データフォルダ構成
dataset/
├─ circle/ ← 円の画像(例:50枚)
├─ square/ ← 四角形の画像(例:50枚)
└─ triangle/ ← 三角形の画像(例:50枚)撮影用のスクリプトを使って効率的に写真を撮りましょう
capture_dataset_camera.py
from picamera2 import Picamera2
import cv2
import time
import os
#保存するラベル名
label = "circle" # circle / square / triangle など
base_dir = "dataset"
save_dir = os.path.join(base_dir, label)
os.makedirs(save_dir, exist_ok=True)
# -----------------------------
# PiCamera2 初期化(640×360)
# -----------------------------
picam2 = Picamera2()
picam2.configure(
picam2.create_preview_configuration(
main={"size": (640, 360)}
)
)
picam2.start()
time.sleep(0.2)
#デジタルズーム防止
try:
sensor_w, sensor_h = picam2.camera_properties["PixelArraySize"]
picam2.set_controls({"ScalerCrop": (0, 0, int(sensor_w), int(sensor_h))})
except:
picam2.set_controls({"ScalerCrop": (0, 0, 2592, 1944)})
time.sleep(0.2)
print(f"学習データ撮影開始: label={label}")
print(" [s] 保存 / [q] 終了")
count = len(os.listdir(save_dir))
while True:
# 生のカメラ画像(保存用)
rgb = picam2.capture_array()
raw_bgr = cv2.cvtColor(rgb, cv2.COLOR_RGB2BGR)
# 表示用画像(ガイド表示に使う)
disp = raw_bgr.copy()
h, w = disp.shape[:2]
# --------------------------------------
# ガイド枠の座標(フレーム中央の四角形)
# --------------------------------------
x1, y1 = w // 4, h // 4
x2, y2 = w * 3 // 4, h * 3 // 4
# ガイド枠描画(画面表示のみ)
cv2.rectangle(disp, (x1, y1), (x2, y2), (0,255,255), 2)
cv2.putText(disp, f"Label: {label} Count: {count}",
(10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0,255,255), 2)
cv2.putText(disp, "[s]=save [q]=quit",
(10, h-10), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255,255,255), 2)
# 表示
cv2.imshow("Capture Dataset (Crop inside guide)", disp)
key = cv2.waitKey(1) & 0xFF
# --------------------------------------
# sキー → ガイド枠の「内側のみ」を保存
# --------------------------------------
if key == ord('s'):
cropped = raw_bgr[y1:y2, x1:x2] # ← ここが重要!
filename = os.path.join(save_dir, f"{label}_{count:03d}.jpg")
cv2.imwrite(filename, cropped)
print("Saved:", filename)
count += 1
elif key == ord('q'):
break
cv2.destroyAllWindows()
picam2.stop()使い方
- スクリプトの
label = "circle"を"square"や"triangle"に書き換え - 図形をカメラの前に置き、中央のガイド枠に収める
sキーで学習画像を保存- クラスごとに20〜50枚撮影したら
qで終了
自動でフォルダが構成されます。
それぞれのラベル名のフォルダの中には連番で以下のような画像ファイルが保存されてゆきます。
円はcircleにまとめましょう。
自分で撮影したデータで学習させる
下記の3つのステップを行います
【Step 1】画像を読み込んで特徴量に変換する
【Step 2】k-NNモデルを学習させる(Training)
【Step 3】実際にリアルタイムで推論(Inference)
k-NNモデルとは
k-NN は機械学習の中でも 最もシンプルでわかりやすい分類の手法 です。
結論から言うと:
「新しいデータが登場したら、その近くにある“k個”のデータの多数決で分類する」
という、とても単純な仕組みです。
例:クラス替えのときに友達の近くに座ると…?
新しい生徒が教室に入ってきたとします。
その生徒が誰と仲良くなりそうかを考えるとき、こんなことを思いませんか?
- 過去に仲良くしていた子 → 同じグループ
- 趣味が似ている子の近くに座る → 同じ趣味グループ
つまり、
似ている人がたくさんいるグループに分類される
ということです。
k-NN も同じです。
画像(図形)を数値化すると「特徴ベクトル」になります。
このベクトル同士の距離を測り、
距離が近い=似ている
距離が遠い=似ていない
と判断します。
あなたの作った dataset には例えば:
- circle(◯)の画像 × 50枚
- square(□)の画像 × 50枚
- triangle(△)の画像 × 50枚
こんな画像がありますね。
k-NN はこれらを全て
各画像の特徴ベクトル(数値の配列)
→ [ピクセル1, ピクセル2, …]
として記録します。
これが学習です。
以下のスクリプトをdatasetフォルダと同じ場所に作成し、実行してみましょう。
train_knn_realdata.py
import cv2
import numpy as np
import os
IMG_SIZE = 32 # 学習用に縮小(32×32が軽くて速い)
# dataset フォルダ構成:
# dataset/circle/
# dataset/square/
# dataset/triangle/
labels = {"circle": 0, "square": 1, "triangle": 2}
train_data = []
train_labels = []
for name, label in labels.items():
folder = f"./dataset/{name}"
print("Loading:", folder)
for filename in os.listdir(folder):
path = os.path.join(folder, filename)
# 画像を読み込む
img = cv2.imread(path, cv2.IMREAD_GRAYSCALE)
# 読み込めない場合はスキップ
if img is None:
continue
# サイズを揃える(学習のため)
img = cv2.resize(img, (IMG_SIZE, IMG_SIZE))
# 1次元の特徴ベクトルに変換
vec = img.flatten().astype(np.float32)
train_data.append(vec)
train_labels.append(label)
print("画像読み込み完了")
# 配列に変換
train_data = np.array(train_data)
train_labels = np.array(train_labels)
# --------------------------
# k-NN モデルを作成して学習
# --------------------------
knn = cv2.ml.KNearest_create()
knn.train(train_data, cv2.ml.ROW_SAMPLE, train_labels)
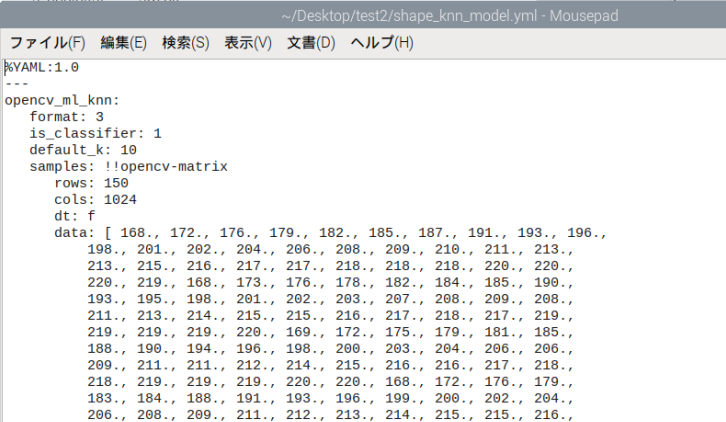
# 学習結果を保存
knn.save("shape_knn_model.yml")
print("学習完了 → shape_knn_model.yml に保存されました!")以下のような学習データが構成されます。
リアルタイムで分類してみる
それでは、あなたが撮影した「実写の図形」を、
学習済みモデルがリアルタイムで認識します。
classify_shapes_real_cam.py
from picamera2 import Picamera2
import cv2
import numpy as np
import time
IMG_SIZE = 32
labels = {0: "circle", 1: "square", 2: "triangle"}
# 学習済みモデルを読み込む
knn = cv2.ml.KNearest_load("shape_knn_model.yml")
# PiCamera2 のセットアップ
picam2 = Picamera2()
picam2.configure(
picam2.create_preview_configuration(
main={"size": (640, 360)}
)
)
picam2.start()
time.sleep(0.3)
# デジタルズーム禁止
try:
sw, sh = picam2.camera_properties["PixelArraySize"]
picam2.set_controls({"ScalerCrop": (0, 0, int(sw), int(sh))})
except:
picam2.set_controls({"ScalerCrop": (0, 0, 2592, 1944)})
print("推論開始(qで終了)")
while True:
# カメラからフレーム取得
frame = picam2.capture_array()
bgr = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
gray = cv2.cvtColor(bgr, cv2.COLOR_BGR2GRAY)
# 中央部分だけ使う(撮影時と同じ領域)
h, w = gray.shape[:2]
x1, y1 = w//4, h//4
x2, y2 = w*3//4, h*3//4
roi = gray[y1:y2, x1:x2]
# 推論用にリサイズ&ベクトル化
resized = cv2.resize(roi, (IMG_SIZE, IMG_SIZE))
vec = resized.flatten().astype(np.float32).reshape(1, -1)
# 推論(k=3 の多数決)
ret, results, neighbours, dist = knn.findNearest(vec, k=3)
label_id = int(results[0][0])
name = labels[label_id]
# 結果表示
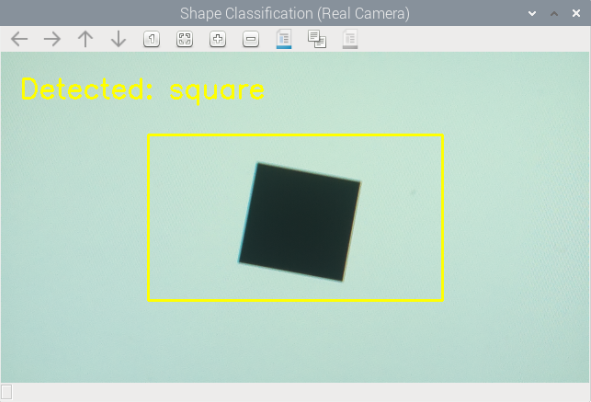
cv2.rectangle(bgr, (x1,y1), (x2,y2), (0,255,255), 2)
cv2.putText(bgr, f"Detected: {name}", (20,50),
cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0,255,255), 2)
cv2.imshow("Shape Classification (Real Camera)", bgr)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
picam2.stop()うまく学習を行えていれば以下のように3種類の図形を判別できるはずです。
新しい画像が来たらどう推論するのでしょうか。
まずは、新しい画像も同じように特徴ベクトルにします。
例:
roi(180×320) → resize(32×32) → flatten → 1024 次元ベクトル① トレーニングデータ全てとの「距離」を計算する
距離は一般にユークリッド距離(直線距離)。
例(2次元の場合)
distance = √((x1-x2)^2 + (y1-y2)^2)今回のデータでは1024次元ベクトルなので
distance = √((v1 - u1)^2 + (v2 - u2)^2 + … + (v1024 - u1024)^2)(実際は高速化のために平方根を省略することもあります)
② 距離が近い順にソートし、上位 “k” 個を取り出す
あなたのコードでは k=3 なので、
最も距離が近い 3 個のデータを選びます。
| 学習データ | 距離 |
|---|---|
| circle_05 | 0.21 |
| circle_12 | 0.25 |
| square_03 | 0.27 |
| … | … |
k=3 なら:
circle, circle, square
③ 多数決で分類
上位3つのラベルを多数決します:
- circle(2票)
- square(1票)
- triangle(0票)
→ 結果:circle
となります。
✔ 良いところ
- アルゴリズムが超シンプル
- 学習が爆速
- 直感的で理解しやすい(教育向け)
- 少量のデータでも使える
✔ 悪いところ
- 推論時に全データとの距離を測るので遅い
- 特徴量のスケールに敏感(正規化が必要な場合あり)
- 背景やノイズの影響を受けやすい
- 次元が高いほど距離比較が難しくなる(次元の呪い)
どんな時に向いている?
- 図形分類
- 「背景が単純」な物体認識
- 少量のデータしかないとき
- 機械学習の導入授業
- プロトタイプの段階
このように機械学習には様々な手法があり、それぞれに特徴がありますので、目的に合わせて調べてみてください。
問題13
データ量と背景の影響を調べてみてください
以下の条件で「circle / square / triangle」を撮影し、
学習データを作成 → k-NNで分類 → 精度を比較しよう。
以下は対照実験を行う際の例です。
条件A:背景・明るさを揃える
- 画像枚数:10枚/クラス
条件B:背景をバラバラにする
背景の色をバラバラにしてみたり、背景に余計なものを映してみたりしてください
- 画像枚数:10枚/クラス
条件C:枚数を増やす(20〜40枚)
同じ条件で画像の枚数だけ増やしてみてください
レポートに書く内容
- 条件A/B/C の分類精度(正解率)を比較
- 誤分類の例(スクショ)
- どの条件が最も高精度だったか?→理由
- 「k-NN の弱点」を自分の言葉で説明する
次回はこちら

\ 最新情報をチェック /