
前回はOpenCV を使った基本的な画像処理を学びました。

いよいよ 画像の中から特定のものを見つける「物体検出」や「認識」 を体験します。
- 画像処理と「特徴」を使ったシンプルな輪郭検出(Contour Detection)
- 形状認識(四角形・円形などを判別)
- 物体認識の考え方(AIモデルを使う手前まで)
- 実際に Pi Camera で撮影した画像を使って輪郭や図形を検出する
OpenCVを使えば、特別なAIモデルを使わなくても、画像中から図形や領域を自動的に見つけることができます。
まずはこの「古典的な画像認識手法」から学んでいきましょう。

物体検出と認識の基本的な考え方
画像の中から物体を見つけるには、主に次のステップに従って行います
撮影 → 画像処理(グレースケール・二値化など)
↓
特徴の抽出(輪郭・形状・色など)
↓
物体を検出(領域を見つける)
↓
認識(「これは○○だ」と分類する)
OpenCV では、機械学習を使わなくても「輪郭」や「形状」「色」などの情報から
シンプルな物体検出・認識を行うことができます。
本日は以下のような画像の形状を判別してみます。
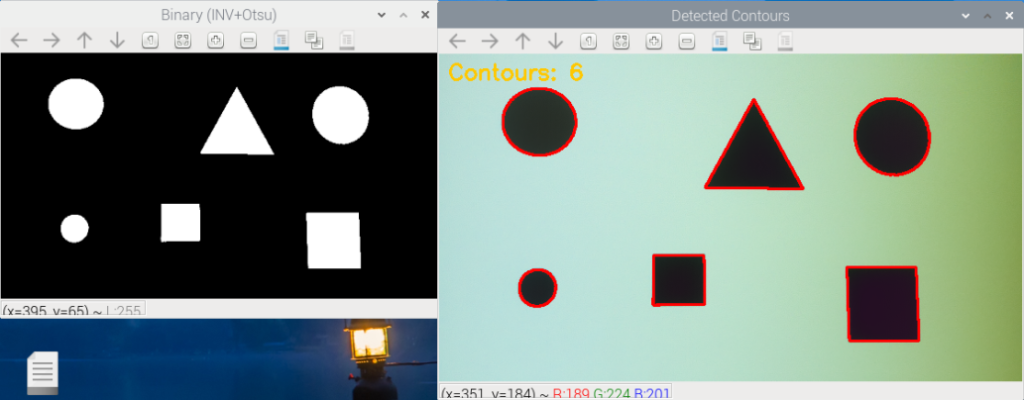
輪郭の検出
まずは Pi Camera で撮影した画像を二値化し、輪郭線を抽出します。
OpenCV の findContours 関数を使うと、二値画像の白い領域の境界線を検出できます。
contour_test.py
# Otsu + 反転 → 輪郭抽出
# Picamera2 + OpenCV
from picamera2 import Picamera2
import cv2, time
def show_small(winname, img, width=640):
"""画像を等比縮小して表示(学習用・任意)"""
h, w = img.shape[:2]
scale = width / w
cv2.imshow(winname, cv2.resize(img, (width, int(h * scale))))
def main():
# カメラ初期化(解像度640x360)
cam = Picamera2()
cam.configure(cam.create_preview_configuration(main={"size": (640, 360)}))
cam.start()
time.sleep(0.2) # 起動安定
# フル視野を使用(デジタルズーム防止)
try:
sw, sh = cam.camera_properties["PixelArraySize"]
cam.set_controls({"ScalerCrop": (0, 0, int(sw), int(sh))})
except:
cam.set_controls({"ScalerCrop": (0, 0, 2592, 1944)})
while True:
# フレーム取得 → RGB→BGR→GRAY
frame = cv2.cvtColor(cam.capture_array(), cv2.COLOR_RGB2BGR)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 二値化(黒物体を白にするため Otsu + INV)
_, binary = cv2.threshold(
gray, 0, 255,
cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU
)
# 最外輪郭のみ抽出
contours, _ = cv2.findContours(
binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE
)
# 輪郭描画
vis = frame.copy()
cv2.drawContours(vis, contours, -1, (0,0,255), 2)
cv2.putText(
vis, f"Contours: {len(contours)}", (10,28),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0,200,255), 2
)
# 縮小表示(見やすさのため)
show_small("Binary (INV+Otsu)", binary, 480)
show_small("Detected Contours", vis, 640)
# s:保存 / q:終了
key = cv2.waitKey(1) & 0xFF
if key == ord('s'):
cv2.imwrite("contours_frame.jpg", vis)
print("Saved: contours_frame.jpg")
if key == ord('q'):
break
cv2.destroyAllWindows()
cam.stop()
if __name__ == "__main__":
main()画像中の物体(白い領域)の輪郭が赤線で表示されれば成功です。
この輪郭は図形の境界を表しており、位置や形状の認識に利用できます。
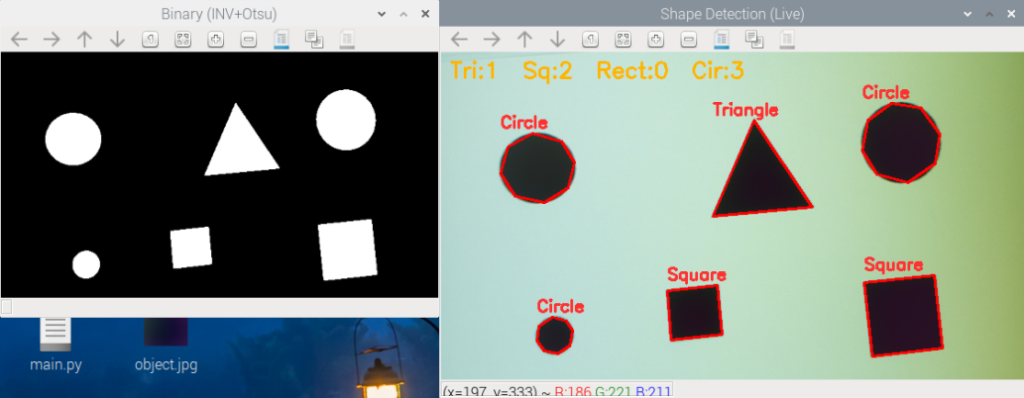
形状の認識
検出した輪郭をさらに解析することで、「これは四角形っぽい」「これは円形っぽい」など形状の判別を行うことができます。
OpenCVでは approxPolyDP を使って輪郭を多角形近似することで、辺の数を調べられます。
# 図形検出(Otsu+反転 → 輪郭近似 → 円形度補強)
# Picamera2 + OpenCV
from picamera2 import Picamera2
import cv2, numpy as np, time
def show_small(winname, img, width=640):
"""等比で縮小表示(学習用・任意)"""
h, w = img.shape[:2]
cv2.imshow(winname, cv2.resize(img, (width, int(h * (width / w)))))
def classify_shape(cnt):
"""輪郭から図形名と近似多角形を返す(小ノイズは除外)"""
area = cv2.contourArea(cnt)
if area < 80: return None, None # 面積でノイズ除外
peri = cv2.arcLength(cnt, True)
approx = cv2.approxPolyDP(cnt, 0.02 * peri, True) # 近似精度=周長の2%
v = len(approx)
if v == 3:
name = "Triangle"
elif v == 4:
x, y, w, h = cv2.boundingRect(approx)
aspect = w / float(h)
name = "Square" if 0.90 <= aspect <= 1.10 else "Rectangle"
else:
circ = (4.0 * np.pi * area / (peri * peri)) if peri > 0 else 0 # 1に近いほど円
name = "Circle" if circ > 0.80 else "Polygon"
return name, approx
def main():
# カメラ初期化(640x480に変更:4:3で視野が自然)
cam = Picamera2()
cam.configure(cam.create_preview_configuration(main={"size": (640, 480)}))
cam.start(); time.sleep(0.2)
# フル視野を使用(デジタルズーム防止)
try:
sw, sh = cam.camera_properties["PixelArraySize"]
cam.set_controls({"ScalerCrop": (0, 0, int(sw), int(sh))})
except:
cam.set_controls({"ScalerCrop": (0, 0, 2592, 1944)})
while True:
# 入力 → RGB→BGR→GRAY → ぼかし → Otsu+反転(黒図形→白)
frame = cv2.cvtColor(cam.capture_array(), cv2.COLOR_RGB2BGR)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray, (3, 3), 0.8)
_, binary = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
# 輪郭(最外)抽出
contours, _ = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 図形分類と描画
counts = {"Triangle": 0, "Square": 0, "Rectangle": 0, "Circle": 0, "Polygon": 0}
vis = frame.copy()
for c in contours:
name, approx = classify_shape(c)
if not name: continue
counts[name] = counts.get(name, 0) + 1
cv2.drawContours(vis, [approx], -1, (0, 0, 255), 2) # 赤:輪郭
x, y, w, h = cv2.boundingRect(approx)
cv2.putText(vis, name, (x, y - 6), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (50, 50, 255), 2)
# 集計表示
summary = f"Tri:{counts['Triangle']} Sq:{counts['Square']} Rect:{counts['Rectangle']} Cir:{counts['Circle']} Poly:{counts['Polygon']}"
cv2.putText(vis, summary, (10, 28), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 180, 255), 2)
# 表示(縮小は見やすさのため)
show_small("Binary (INV+Otsu)", binary, 480)
show_small("Shape Detection (Live)", vis, 640)
key = cv2.waitKey(1) & 0xFF
if key == ord('s'):
cv2.imwrite("shape_live_frame.jpg", vis); print("Saved: shape_live_frame.jpg")
if key == ord('q'):
break
cv2.destroyAllWindows(); cam.stop()
if __name__ == "__main__":
main()三角形・四角形・円形が検出できた場合、それぞれの形の名前が画像に描かれます。
この方法は、ロボットが床に置かれた目印(マーカー)の形を認識する用途などにも使えます。
物体検出と認識の応用
ここまで扱った方法は、「しきい値」「輪郭」「形の頂点数」といった画像処理ベースの手法です。
一方、近年の物体認識は「機械学習(AI)」による分類が主流です。
| 手法 | 特徴 | 向いている場面 |
|---|---|---|
| 画像処理ベース | 高速・シンプル。特定の形や色を検出できる | ロボットのマーカー検出、簡易分類など |
| AIベース(学習) | 柔軟で高精度。複雑な対象も分類可能 | 人・モノの認識、複雑な背景の検出など |
例えば、AIベースでは YOLO(You Only Look Once)や MobileNet などのモデルを使って
「犬」「猫」「人」などを判定できますが、今回はそこまで踏み込みません。
まずは「形を見つける」ことから始めるのが大切です。
問題8
現在のプログラムでは cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU を使って自動で二値化しています。
これをやめて、手動でしきい値を指定する方式に書き換えましょう。
cv2.createTrackbar を使い、リアルタイムでしきい値を変更しながら結果を観察できるようにしてください。
ヒント:
cv2.threshold(gray, value, 255, cv2.THRESH_BINARY_INV)を使うvalueを Trackbar で変更できるようにする- 輪郭の数や認識結果がどのように変化するか観察する
回答例はこちら
# 手動しきい値 → 反転二値化 → 輪郭表示(Trackbarで調整)
# Picamera2 + OpenCV
from picamera2 import Picamera2
import cv2, time
def show_small(winname, img, width=480):
"""等比縮小して表示(学習用・任意)"""
h, w = img.shape[:2]
cv2.imshow(winname, cv2.resize(img, (width, int(h * (width / w)))))
def nothing(x): pass
# カメラ初期化(640x360)
cam = Picamera2()
cam.configure(cam.create_preview_configuration(main={"size": (640, 360)}))
cam.start(); time.sleep(0.2) # 起動安定待ち
# フル視野を使用(デジタルズーム防止)
try:
sw, sh = cam.camera_properties["PixelArraySize"]
cam.set_controls({"ScalerCrop": (0, 0, int(sw), int(sh))})
except:
cam.set_controls({"ScalerCrop": (0, 0, 2592, 1944)})
# Trackbarウィンドウ(手動しきい値)
cv2.namedWindow("Controls")
cv2.createTrackbar("Threshold", "Controls", 100, 255, nothing)
while True:
# 取得→RGB→BGR→GRAY
frame = cv2.cvtColor(cam.capture_array(), cv2.COLOR_RGB2BGR)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 手動しきい値(白背景×黒物体を白化するため反転)
t = cv2.getTrackbarPos("Threshold", "Controls")
_, binary = cv2.threshold(gray, t, 255, cv2.THRESH_BINARY_INV)
# 最外輪郭のみ抽出→描画
contours, _ = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
vis = frame.copy()
cv2.drawContours(vis, contours, -1, (0,0,255), 2)
cv2.putText(vis, f"Threshold={t}", (10,30), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (255,255,0), 2)
# 表示(縮小は見やすさのため)
show_small("Binary (INV)", binary, 480)
show_small("Contours", vis, 640)
# qで終了 / sで保存(任意)
key = cv2.waitKey(1) & 0xFF
if key == ord('s'):
cv2.imwrite("manual_thresh_contours.jpg", vis); print("Saved: manual_thresh_contours.jpg")
if key == ord('q'):
break
cv2.destroyAllWindows(); cam.stop()cv2.threshold()の第2引数に手動で設定した値を使っています。
- Trackbarを動かして値を上下させると、背景と物体の二値化境界がリアルタイムで変わる様子が確認できます。
- 明るい背景では適切なしきい値(例:100〜150)が必要ですが、暗くすると輪郭が欠けたりノイズが増えたりします。
- Otsu法は最適値を自動で計算するのに対し、この課題ではその裏にある「しきい値による白黒分類の挙動」を体感できます。
問題9
輪郭を検出したあと、それぞれの図形について以下を表示してください:
- 中心座標(x, y)
- 面積(pixel数)
- 図形名(Triangle, Square, Rectangle, Circle)
それらを図形の上に cv2.putText() で描画してください。
ヒント:
cv2.moments()を使うと重心座標を計算できます。cv2.contourArea(cnt)で面積を求める- 面積が極端に小さい輪郭はノイズとして除外するとよい
M = cv2.moments(cnt)
cx = int(M["m10"]/M["m00"])
cy = int(M["m01"]/M["m00"])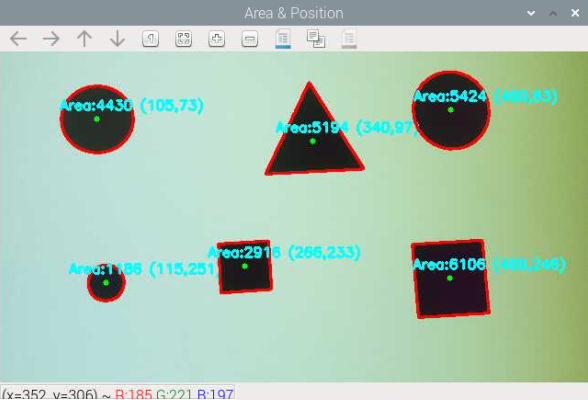
解答例はこちら
# 面積と重心を表示(Otsu+反転 → 輪郭 → モーメント)
# Picamera2 + OpenCV
from picamera2 import Picamera2
import cv2, numpy as np, time
def show_small(winname, img, width=480):
"""等比で縮小表示(学習用・任意)"""
h, w = img.shape[:2]
cv2.imshow(winname, cv2.resize(img, (width, int(h * (width / w)))))
def main():
# カメラ初期化(640x360)
cam = Picamera2()
cam.configure(cam.create_preview_configuration(main={"size": (640, 360)}))
cam.start(); time.sleep(0.2) # 起動安定待ち
# フル視野を使用(デジタルズーム防止)
try:
sw, sh = cam.camera_properties["PixelArraySize"]
cam.set_controls({"ScalerCrop": (0, 0, int(sw), int(sh))})
except:
cam.set_controls({"ScalerCrop": (0, 0, 2592, 1944)})
MIN_AREA = 50 # 小さいゴミを除外
while True:
# 取得→RGB→BGR→GRAY
frame = cv2.cvtColor(cam.capture_array(), cv2.COLOR_RGB2BGR)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# Otsu + 反転(二値化:黒物体を白に)
_, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
# 最外輪郭のみ
contours, _ = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
vis = frame.copy()
for cnt in contours:
area = cv2.contourArea(cnt)
if area < MIN_AREA: # 面積でノイズ抑制
continue
# モーメントから重心 (cx, cy)
M = cv2.moments(cnt)
if M["m00"] == 0: # 0除算の回避
continue
cx, cy = int(M["m10"] / M["m00"]), int(M["m01"] / M["m00"])
# 輪郭・重心・情報表示
cv2.drawContours(vis, [cnt], -1, (0, 0, 255), 2)
cv2.circle(vis, (cx, cy), 3, (0, 255, 0), -1)
cv2.putText(vis, f"Area:{int(area)} ({cx},{cy})",
(max(cx - 40, 0), max(cy - 10, 12)),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 0), 2)
show_small("Area & Position", vis, 640)
key = cv2.waitKey(1) & 0xFF
if key == ord('q'): # 終了
break
cv2.destroyAllWindows(); cam.stop()
if __name__ == "__main__":
main()cv2.contourArea()→ 図形のピクセル面積を取得cv2.moments()→ 輪郭のモーメントから重心(cx, cy)を計算- 小さなノイズ輪郭は面積でフィルタすることで安定した処理が可能になります。
- 重心と面積を使うことで、「大きさ」や「位置」を数値で扱えるようになり、ロボット制御や物体追跡の基礎になります。
次回はこちら

\ 最新情報をチェック /